Content Aggregation
In his book Why Information Grows: The Evolution of Order, from Atoms to Economies
The author calculates that the Bugatti – which has a sticker price of $2.5 million – is worth $600 per pound. This is quite a bit more than the $10 per pound of a Hyundai or even the $60 per pound of a BMW.
Now imagine that you ran the Bugatti into a wall at 100 m.p.h. Assuming you survived the crash and then gathered up every last piece of the car, it would still weigh the same as the instant before it hit the wall. But it wouldn’t be worth nearly $600 per pound any longer. It’s the same steel, rubber, and glass it was, it’s just not in the same form.
Here’s the key:
The dollar value of the car evaporated in the seconds it took you to crash it against that wall, but its weight did not. So where did the value go? The car’s dollar value evaporated in the crash not because the crash destroyed the atoms that made up the Bugatti but because the crash changed the way in which these parts were arranged. As the parts that made the Bugatti were pulled apart and twisted, the information that was embodied in the Bugatti was largely destroyed.
The last sentence is key: the value of the Bugatti wasn’t in the raw materials of the car, but rather in how these materials were arranged and ordered. Value is created by putting smaller pieces together to work as a whole. The selection, combination, and ordering of the parts is more valuable than the parts themselves.
Likewise, content often becomes more valuable when combined with other content. These combinations are called aggregations. In some senses, an aggregation of content becomes content itself. The “content,” in this case, is in the selection, combination, and ordering of smaller content items to come together to form a new whole.
Content aggregation is the ability or a CMS to group content together. Note that we’re not being too specific here – there are many types of aggregations and many ways a CMS might accomplish this. Furthermore, this ability is so obvious as to be taken for granted. We tend to simply assume every CMS does this to whatever degree we need.
For example:
- Displaying navigation links is aggregation. At some point, you need to tell your CMS to display a series of pages in a specific order to form the top menu of every page (a static aggregation that is manually ordered).
- Index pages are aggregations. The page that lists your latest press releases is often simply a canned search of a specific content type, limited to the top 10 or so, and displayed in descending order chronologically (a dynamic aggregation with derived ordering).
- Search is aggregation. When a user enters a search term and gets results back, this is a grouping of specific content (a dynamic, variable aggregation).

An aggregation of news releases on IBM’s website as of December 2014
Aggregation is such a core part of most systems that it’s assumed and often isn’t even identified as a separate subsystem or discipline. But the range of functionality in this regard is wide, and breakdowns in this area are enormously frustrating.
Few things are more annoying than having the content you want, but being unable to retrieve it in the format you need. I’ve been in numerous situations working with multiple systems where editors threw up their hands in frustration and said, “All I want is to make this content appear in that place! Why is this so hard!?”
The answer to that question lies in a complex intersection of content shape, aggregation functionality, and usability.
The Shape of Content
The shape of content refers to the general characteristics of a content model when taken in aggregate and when considered against the usage patterns of your content consumers. Different usage patterns and models result in clear differences between content and its aggregation requirements. Content may be:
Serial: This type of content is organized in a serial “line,” ordered by some parameter. An obvious example is a blog, which is a reverse-chronological aggregation of posts. Very similar to that are social media updates – a tweet stream, for instance – or a news feed. This content doesn’t need to be organized in any larger construct beyond where it falls in chronological order relative to other content. A glossary might be considered serial as well – it’s a simple list of terms, ordered alphabetically by title.
Hierarchical: This type of content is organized into a tree. There is a root content object in the tree that has multiple children, each of which may itself have one or more children, and so on. Sibling content items (those items under the same parent) can have an arbitrary order. Trees can be broad (lots of children under each parent) or narrow (fewer children) and shallow (fewer levels) or deep (more levels). An example of this is the core pages of many simple informational websites. Websites are generally organized into trees – there is primary navigation (Products, About Us, Contact Us), which leads to secondary navigation (Product A, Product B, etc.). Navigational aggregations for these sites can often be derived from the position of content objects in the tree.
Tabular:
This type of content has a clearly defined structure of a single, dominant type, and is usually optimized for searching, not browsing. Imagine a large Excel spreadsheet with labeled header columns and thousands of rows. An example would be a company locations database. There might be 1,000 locations, all clearly organized into columns (address, city, state, phone number, hours, etc.). Users are not going to browse this information. Rather, they search it based on parameters.
Network: This type of content has no larger structure beyond the links between individual content objects. All content is equal, flat, and unordered in relation to other content, with nothing but links between the content to tie it together. An obvious example of this is a wiki. Wikis have no structure (some allow hierarchical organization of pages, but most do not), and the entire body of content is held together only by the links between pages. A social network – if managed as content – would be another example. Content (“people”) is equal in the network, and arbitrarily connected (“friends”) with other content.
Relational: This type of content has a tightly defined structural relationship between multiple highly structured content types, much like a typical relational database. The Internet Movie Database, for example, has Movies, which have one or more Actors, zero or more Sequels, zero or more Trivia Items, etc. These relationships are enforced – for instance, you cannot add a Trivia Item for a Movie that doesn’t exist. A Trivia Item is required to be linked to a Movie, and cannot be added until the Movie exists.
Different CMSs have different levels of ability to handle the different shapes of content. For example:
- WordPress is well suited to managing serial content (blog posts), but you couldn’t easily run a highly hierarchical help topic database with it.
- MediaWiki is designed to handle networked content, but it would be extremely inefficient to try to run a blog from it.
- Webnodes is perfect for defining and managing tabular and relational content. Interestingly, this also gives it the ability to manage serial content well (a blog is essentially a database table ordered by a date field), but it wouldn’t make sense to highly structure a networked wiki with it. The image below shows an example of a complicated relational content model implemented in Webnodes.

A complex relational content model as supported by Webnodes
In our examples, we simplified by pigeonholing websites to one shape, but the truth is that different sections of the same website will model content differently. The average corporate website might have many marketing pages organized into a tree (hierarchical), a dealer locator (tabular), and a news feed (serial). The content managed in each section has a different shape.
Additionally, when we say a particular system is not suited to a particular shape of content, what we’re saying is that this system is not best suited to work with that shape of content. It’s important to note that almost any system can be contorted to work with any type of content, though this either requires heroic development efforts or results in a very complex and confusing editor experience (often both).
Most mainstream CMSs are pursuing the middle of the road. They are usually particularly well suited to one or more of the listed shapes, but have some ability to handle any of them.
Content Geography
Most every system has some core method of organizing content. Very rarely do editors just throw content into a big bucket – normally, content is created somewhere, which means it exists in a location relative to other content.
Much like geography refers to the spatial relationships of countries, content geography refers to the spatial nature of content – where it exists “in space,” or how it is organized relative to the content “around” it.
The quotes in that last paragraph underscore the idea that we’re trying to place some physical characteristic on an abstract concept. Geographies attempt to treat content as a physical thing that exists in some location in a theoretical space representing the domain of all of your content.
The most common example of a geography is a “content tree” where content is organized as a parent/child structure. All content objects can be the parent of one or more other content objects. Additionally, each object has its own parent and siblings (unless it’s the root object, which means it’s at the very top of the tree).
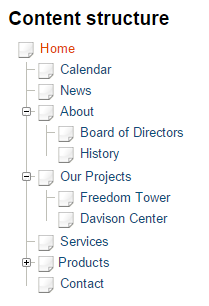
A typical content tree in an eZ Platform – powered website
In this sense, all content is created in some location. You add content as a child of some other content object, and because of this, it instantly has relationships with multiple other content objects. Depending on where it’s placed, it might come into the world with siblings and (eventually) might have children, grandchildren, etc.
This content is hierarchical, and this geography allows us to traverse the tree and make decisions based on what we find. For instance, we may form our top navigation automatically from the children of the root object, or we may list the children of a certain page as navigation options when displaying that page to a user.
In a content tree geography, content is often discussed in terms of “levels.” The most important pages in your site are top-level pages or first-level pages. Under that we have second-level pages, then third-level pages.
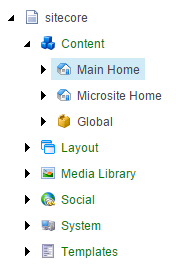
An example of a global tree from Sitecore – this system stores almost every bit of data in a tree structure, including templates and system settings
Less common is the folder structure of organizing content. Systems using this model have “folders” into which content can be placed, similar to files in an operating system.
This might seem very similar to the content tree in that it’s hierarchical, but there’s an important difference: the folder is not itself a content object. It’s simply an administrative structure for editors to use to organize their content. Content objects are not children of other content objects, nor do they have children. Instead, we have folders and subfolders in which content objects are placed.
While this structure is generally clear for editors – we’ve been using files and folders for years in every operating system – it can be limiting in practice. The inability to directly relate content by parentage removes a valuable tool to aggregate content.
If we can’t have children of a page, then we have to find another way to tie these pages together. The only spatial relationship content in these system exhibits is a sibling relationship with content in the same folder. (What makes this more complicated is that folders are often treated as simple buckets that don’t allow arbitrary ordering of the content within them – more on that later in this chapter.)
Other systems might depend on a simple content type segregation model, where the content type of a particular piece of content is the major geography

Listing content by type in Drupal
Like the folder structure, this can limit our options considerably, but it can be appropriate in many cases. For instance, if your website is a high-volume blog, then your editors might not need to “place” their content anywhere. They might just need to create a Blog Post or a Movie Review and let the system itself sort out how to organize it. In these situations, editors are creating serial, isolated content that doesn’t need any spatial relationships (or, rather, its spatial relationship to other content is automatically derived by date).
It’s important to understand that a content geography is simply the main organization method a system exhibits. Systems usually offer multiple ways to aggregate content, so when the core geography falls short there are typically multiple paths to accomplish the desired aggregation.
Editorial Limitations on Geography
Having editors intentionally “placing” content in a specific location in a geography might not be ideal. As we discussed in The Content Management Team, there are different ways that editors’ capabilities can be limited.
There are some editors who have limited responsibilities and might only be able to create certain types of content that can fit into the geography in one tightly controlled way. In these cases, you can limit them with permissions, but you might instead create a very simple interface for these editors to work with content.
The receptionist who manages the lunch menu on your intranet, for example, might only see a simple text box that allows him to enter some text for the next day’s menu. Behind the scenes, this interface places the content in the correct location relative to the larger geography without the editor being aware of it or being able to affect it in any way.
Secondary Geographies: Categories, Taxonomies, Tags, Lists, Collections, and Menus
When we talk about a geography of content, we’re normally talking about the main way a CMS organizes its content. However, many systems have additional ways of grouping content, which might be pervasive enough to be considered secondary geographies.
Many systems are explicitly menued, which means there are menuing subsystems in which you create organizational structures and assign content to them. Menuing systems are generally very practical, in that they have to directly generate an HTML structure at some point. They’re less about pure content, and more about providing an interface to generate a specific snippet of HTML. As such, you can assign content to a menu, but you also usually assign external URLs and sometimes even specify presentational information, like whether to open the link in a new window or whether to use an image in place of text. You sometimes even get all the way down to CSS classes and other details.
Menus are almost always hierarchical. This leads to the sometimes odd situation of having multiple trees. If your system uses a content tree as its core geography, you might have menus where relationships are reversed. Object B could be a child of Object A in the actual content tree, but Object A might be a child of Object B in one or more menu trees. This can either be handy or confusing, depending on the situation.
Some systems have flat structures they call lists or collections. These are just ordered lists of content which can be used in dozens of ways to aggregate content around a website. (Of course, a single-level menu, where the top-level items have no children, will basically accomplish the same thing.)
Categories, taxonomies, and tagging are other popular ways to organize content. Content objects can be assigned to a category or tag, which gives them some affinity relationship with other content in that category or tag, much like content in a folder or child content under a parent. The relationships in these secondary structures don’t have to bear any resemblance to how content is organized in the primary structure.
Editors might find it easier to organize or relate to content in this way, and there are numerous ways to use these secondary geographies to display content to the end user.
In general, content geographies are administrative concepts only. Visitors to a website will not usually be aware of the underlying geography. They may be vaguely aware that pages are ordered hierarchically, or that news items are ordered by date. However, at no time will the average website call attention to the content tree (with the possible exception of a sitemap) or explicitly name pages as “parent” or “child.”
The Tyranny of the Tree
Content trees are very common in CMSs, but they can be problematic when large portions of functionality are bound to a single tree. In these cases, you can find that the tree exerts tyrannical control over your content, and simple problems become harder to resolve.
For instance, in various systems, the following functionality might be in some way related to where a piece of content resides in the tree:
- Permissions
- Allowed content types
- Workflow
- URL
- Template settings
If there’s only one tree, then the tree can seem “tyrannical,” forcing all this functionality onto content based solely on its position. For instance, you might group content into one location in the tree to make assigning permissions easier, but want more granular control over template selection than the tree position allows.
In these cases, a system needs to allow for settings and configuration to depart from the tree in some way. Applying this information based on tree position can certainly be efficient, but it might cross the line into restrictive, and a system needs to allow an intelligent and intuitive way to override this when necessary.
Additionally, binding navigation to a content object’s position in the tree can become problematic when the same link needs to appear in two places on the site. If the website navigation is generated by traversing the tree, you are limited to what is present in the tree. If content needs to be in two places, how do you handle this?
Thankfully, most systems using a content tree have some mechanism for content to appear in more than one location. Usually, one of the appearances is designated as the “main” location, and the second is just a placeholder that references the first. Navigation can be handled one of two ways: the second location actually sends the user “across the tree” to the first location, or it renders the content “in place,” essentially giving the same content two URLs. In practice, the former option is usually preferred.
When rendering external navigation links (to another website), these usually have to be represented by a content object. A type named External Url, or something similar, is modeled to contain the URL to which the editor wants to link. When rendered in navigation, this object displays a hyperlink offsite.
Aggregation Models: Implicit and Explicit
There are two major models for building aggregations:
- Implicit/internal
- Explicit/external
Content can implicitly be created as part of a larger structure. This is common in the content tree and type segregation models. When you create the page for Product X under the Products page, you have created a relationship. Those two pages are inextricably bound together as parent and child.
Put another way, their relationship is internal (or “implicit”) – each content object knows where it lives in the structure. The fact that Product X is a child of Products, or that your Press Release is part of the larger aggregation of all Press Releases, is a characteristic that is inextricable from the content.
Conversely, an explicit aggregation means the relationship between these two content objects doesn’t reside in the objects themselves. If we relate two objects in the Main Menu, the fact that Product X is a child of Products is only true in relationship to the Main Menu we created. Taken in isolation, the two content objects don’t know anything about each other or their relationship in this menu. The structure in these cases is external (or “explicit”). The structure doesn’t exist within the content itself, but rather in a separate object – the menu. If that menu goes away, so does the relationship.
One of the benefits of explicitly creating aggregation structures is that content can take part in more than one structure. You might have a dozen different menus in use around your site, and the Products page could appear in all of them.
Should Your Aggregation Be a Content Object?
In some cases, your aggregation is really a managed content object with relationships to other content. However, most systems don’t treat aggregations as core content objects, which means they’re locked out of a lot of the functionality we consider inherent in the management of content. Sometimes, turning an aggregation into a content object is the right way to go.
Consider your team of technical writers. They would like to maintain several lists of help topics centered around certain subjects – topics about dealing with difficult customers, topics about the phone system, etc. These lists will always be manually curated and ordered, and each list should have a title, a few sentences of introductory text, and a date showing when the list was created and last reviewed.
Clearly, this is less of an aggregation and more of a full-fledged content object. Referring back to the concepts discussed in Content Modeling, this situation would call for a new content type: Topic List. It would have attributes of Title, Introduction, Date Created, Date Reviewed, and Topics. That last attribute would be a reference to multiple Help Topic objects from elsewhere in the geography.
By making this aggregation a content object, we gain several inherent features of content:
- Permissions: We could allow only certain editors to manage a particular Topic List.
- Workflow: Changes to a Topic List might have to be approved.
- Versioning: We might be able to capture and compare all changes to a particular Topic List.
- URL addressability: This aggregation now has a URL from which it can be retrieved (more on this in the next section).
When modeling content relationally, the line between content objects and content aggregations blurs because a referential attribute that allows multiple references is a small aggregation in itself. In these ways, aggregations can be “carried” on the backs of content objects.
Consider that the composition of an aggregation is really content in itself. A list of curated content objects, placed in a specific order, fulfills the two tests of content from What Content Management Is (and Isn’t): it’s (1) created by editorial process, and (2) intended for human consumption. Not treating this aggregation as content can lead to problems.
Let’s say your organization is legally required to list hazardous materials used in its manufacturing process on the company intranet. Someone might accidentally remove all the items from this list, putting the organization in violation of the law. How did the editor get permissions to do this? Did this change not trigger an approval? Could the organization not roll back to a previous version of the list?
Not every aggregation is as critical as this example, but in many cases, aggregations are not backed by the safeguards associated with other content objects. When planning and designing aggregations, your requirements might dictate that they be treated more like content.
The URL Addressability of Aggregations
In many systems, the only data structures that are assigned URLs are full-fledged content objects. This means that aggregations like menus, lists, and tags are not URL addressable – no visitor can type in a URL and view a menu, for instance.
In these cases, aggregations need to be “wrapped” in content objects in order for them to be displayed. For example, to create a list of content, an editor might have to create a Page object, then somehow embed this aggregation inside the page. Then, a visitor isn’t viewing the aggregation so much as viewing the particular content object in which the aggregation is being displayed. Displaying the aggregation becomes indirect.
Not all systems work this way, though. Some systems have different mechanisms for assigning URLs to explicit aggregations and allowing them to be directly displayed as the target of a URL.
Aggregation Functionality
Content aggregations can have multiple features, the presence or absence of which will drastically affect an editor’s ability to get the result she wants.
Static Versus Dynamic
A particular aggregation might be static, which means an editor has arbitrarily selected specific content objects to include in the aggregation, or dynamic, meaning the content of the aggregation is determined at any particular moment by specified criteria:
A static aggregation might be an index of pages from your employee handbook that new employees should review. In this case, you have specifically found these pages and included them in this aggregation via editorial process. For a new page to be on this list, you need to manually include it.
A dynamic aggregation might simply be a list of all of the pages of the employee handbook. For a new page to be on this list, it just needs to be added to the employee handbook. Its appearance on this list is a byproduct of that action. A dynamic aggregation is essentially a “canned search” – a set of search criteria which are executed at any moment in time to return matching content.
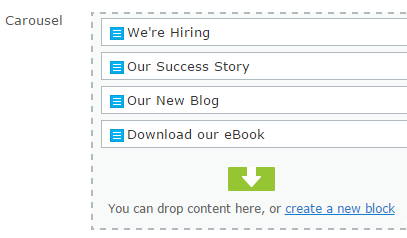
A statically created list of content for an image carousel in Episerver
Dynamic aggregations are often a byproduct of the content geography. In the case of a content tree, the set of children of a parent page is a dynamic aggregation. With all such systems, it’s possible to obtain an aggregation of child pages, and a new item will appear in this aggregation simply by virtue of being created under the parent. This is no different than a canned search with the criterion that the returned content must be the children of a particular parent.
Likewise, a dynamic aggregation might be “show me all the News Releases.” In a system relying on type segregation as its core geography, simply adding a new News Release content object will cause a new item to appear in this aggregation.
Search criteria in dynamic aggregations
When creating a dynamic aggregation, editors will be dependent on the criteria that the CMS allows them to use to search for content, and the interface that the CMS gives them to configure it. They might be able to search by type, by date published, by author, and perhaps by property value.
When these methods fall short, it can be extremely frustrating. Either the CMS is deficient, or the editor simply wants to aggregate content using such an esoteric combination of criteria that no CMS can reasonably be expected to provide that level of specificity.
For example, suppose your editor wants to display an aggregation of all News Release objects from 2015 that are categorized under “Africa,” but only when the text doesn’t contain the phrase “AFRICON 2015” (since the preparations for a particular conference in Africa might confuse the results). Also included should be anything that contains the word “Africa” from any category, and any News Release written by an author assigned to a location in Africa during 2015.
There may be some CMSs that allow editors to configure this level of specificity from the interface, but they’re few and far between. In these situations, it’s usually necessary to have a developer assist by creating a custom aggregation from code.
Variable Versus Fixed
A subset of dynamic aggregations are those that can vary based on environmental variables. Even if the domain of content doesn’t change and no content is added or altered, what appears in a dynamic aggregation might be different from day to day, or user to user.
Search is a classic example of a dynamic, variable aggregation. What is displayed in a search results page depends primarily on user input – what the user searches for. You may specify some other criteria, such as what content is searched and how the content is weighted or ordered, but a search is still created in real time based on user input.
Other aggregations might also be based on user behavior. For example, a sidebar widget displaying Recommended Articles might examine the content consumed by that visitor during the current session to determine similar content of interest.
Aggregations might be based on other variables, too – a “This Day in History” sidebar listing events, for example, clearly relies on the current date to aggregate its contents. Likewise, a list of “Events Near You” relies on a geolocation of the visitor’s latitude and longitude.
Manual Ordering Versus Derived Ordering
Once we have content in our list, how is it ordered? What appears first, second, third, and so on? In some cases, we need to manually set this order. In other cases, we need or want the order to be derived from some other criteria possessed by the content itself:
In the case of our employee handbook, if we were creating a curated guide of pages that new employees should read, then in addition to manually selecting those pages, we’d likely want to arbitrarily decide the order in which they appear. We might want more foundational topics to appear first, with more specific topics appearing further down the list.
If we had a list of Recently Updated Handbook Topics, then in addition to this list being dynamic (essentially a search based on the date the content was changed), we would want this content ordered reverse-chronologically, so the most recently updated topics appeared first. We would simply derive the search ordering by date.
It’s obvious from our examples that the characteristics of static vs. dynamic and manual ordering vs. derived ordering often go hand in hand. It’s relatively rare (though not impossible) to find an arbitrary aggregation that should have derived ordering. However, in most cases, if editors are manually aggregating content they also want the ability to manually order it.
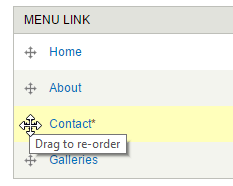
Manually reordering a menu in Drupal
The opposite scenario – a dynamic aggregation that is manually ordered – is logically impossible. This gets a little abstract, but if an aggregation is dynamic, then its contents are not known at creation time (indeed, you’re not building an aggregation as much as simply configuring search parameters), so there’s no way this aggregation can be manually ordered. You can’t manually order a group of things if the contents are unknown.
Manual ordering of dynamic aggregations can be approximated by “weighting” or “sort indexing,” whereby content type has a property specifically designed to be used in sorting.
This works in most cases, but it can be quite loose. If one page has a sort index of 2 and another has an index of 4, then there’s nothing stopping an editor from inserting something at index 3. Indeed, in many cases this is what the editor wants to do, but in other cases editors might do this in ignorance of the consequences (remember, they’re editing the content itself, not the content’s inclusion in the larger aggregation – they may not even be aware of the larger aggregation).
Furthermore, to allow this type of ordering, you need to have a different sort index for every single dynamic aggregation in which the content might appear. You would need some way to say, “Weight this result by X when Bob searches for ‘party,' but weight it at Y when Alice searches for gathering.”
Obviously, this is nigh impossible. Dynamic aggregations, by definition, can be created to execute arbitrary searches, so there’s no way to speculate on the sum total of all aggregations in which a content object might appear, nor is it possible to speculate on the other content in any particular aggregation, so as to manually tune a sort index.
Suffice to it say that in very few cases is it possible to manually order a dynamic aggregation of content.
Type Limitations
It’s not uncommon to only allow certain content types in specific aggregations. If the aggregation is dynamic and we specify the type in our search criteria (“show me all the News Releases”), then this is natural. However, in other situations, we might want to limit types because the content has to conform to a specific format in order to be used in the output.
For instance, consider the image carousel frame depicted below. This is one frame of a multiframe gallery, powered by an aggregation (a flat list or collection) of multiple content objects. This list is manually created and ordered.

An image carousel frame – the image carousel itself is an aggregation that depends on all its content being of a specific type
To render correctly, every item in this aggregation must have:
- A title
- A short summary
- An image
- Some link text (the “Read the Article” text)
- A permanent URL (to route visitors to when they click on the link text)
Only content conforming to this pattern can be included in this aggregation. This means, for example, that an Employee Bio is out, because it doesn’t have a summary.
Since this aggregation is most likely static (image carousels are always curated lists of content), then we need a way to limit editors to only select content that is of the type we need. If we can’t limit by type, then we run the risk of our image carousel breaking if it encounters content not of the type it needs.
A smart template developer will account for this and simply ignore and skip over content that doesn’t work. This prevents errors, but will likely confuse an editor who doesn’t understand the type limitations and might result in a panicked phone call: “My new image isn’t appearing in the front page carousel!”
These limitations are not uncommon in content tree geographies. It’s quite common to be able to specify the type of content that can be created as a child of other content. For example, we might be able to specify that a Comment content type can only be created as a child of a Blog Post content type, and the inverse – Blog Posts can only accept children that are Comments.
Quantity Limitations
This is less common, but some aggregations can store more content than others, and some systems allow you to require a certain number of content objects, or prevent you from going over a maximum.
Consider our image carousel – it might need at least two items (or else it’s not a carousel) and be limited to a maximum of five (or else the pager formatting will break). It will be helpful if the interface can limit editors to adding items only within those boundaries.
Permissions and Publication Status Filters
In one sense, an aggregation – be it static or dynamic – should be a “potential” list of content. Every aggregation on a site should be dynamically filtered for both the current visitor and the publication status of the content in it.
If you manually create an aggregation with ten items, but the current visitor only has permission to view three of them, what happens? Ideally that list should be dynamically filtered to remove the seven items that shouldn’t be viewed. The same is true with publication status, and specifically start and end publish dates. IF the current date is prior to the start date of the current (or after the end date), then it shouldn’t be included.
What this means is that an aggregation – even a static one – might show different content for different visitors, and under certain conditions some visitors might not see any content at all. This is an edge case that your template developer should be aware of and will need to account for.
Flat Versus Hierarchical
Many aggregations are simply flat – our list of employee handbook pages, for example, or our image carousel. But other aggregations are often hierarchical structures of content.
In these cases, we have multiple flat aggregations with relationships to each other. A hierarchical list is basically multiple flat lists nested in one another. The top level is one flat list, and each subsequent level can either be a single content object or another flat list, and so on all the way down. The only difference (and it’s an important one) is that these flat aggregations are aware of each other – any one of them knows that it has children, or a parent.
The main menu for a website is a clear example. Websites often have an overhead menu bar that either contains drop-down submenus for second-level pages, or secondary navigation that appears in the sidebar menu
Interstitial Aggregations
In some situations, the inclusion of content in an aggregation requires additional information to make sense. In these cases, the inclusion of content becomes a content object in itself.
For example, let’s say we’re aggregating a group of Employee Bio content objects to represent the team planning the company Christmas party. To do this, we will create a static aggregation of content.
However, in addition to the simple inclusion in this aggregation, we want to indicate the role each employee plays in the group represented by the aggregation. So, in the case of Mary Jones, we want to indicate that she is the Committee Chair. Mary is actually the receptionist at the company, and this is the title modeled into her Employee Bio object.
The title of Committee Chair only makes sense relative to her inclusion in this aggregation, and nowhere else. Therefore, this attribute is neither on the aggregation nor on the Employee Bio. This attribute rightfully belongs on the attachment point between the two; it “decorates” Mary’s assignment to this committee.

The title “Committee Chair” belongs to neither Mary nor the committee; rather, it correctly belongs to the intersection between the two
In this sense, her inclusion in this aggregation is a content object in itself, and our committee is really an aggregation of Committee Assignment content objects, which are modeled to have a Title and a reference to an Employee Bio. The Employee Bio object is included in the aggregation “through” a Committee Assignment object, for which we need a new content type.
Now, clearly, this gets complicated quickly, and this isn’t something you would do for a one-off situation. But if situations like this are part of your requirements, then modeling an aggregation assignment as a content type by itself can allow you to model the relationships.
By Configuration or By Code
As we briefly discussed in Points of Comparison, certain things in a CMS environment can be accomplished by non-technical editors working from the interface, and other tasks need to be handled by developers working with the templating or the core code of the system.
Aggregations are no different. As a general rule, developers can aggregate content any which way the API allows – they have complete freedom. A subset of these capabilities are provided to editors to create and display aggregations as part of content creation. How big this overlap is depends highly on the system, and partially on the sophistication of your editors.
Aggregations can get complicated. A list of blog posts seems quite simple, but the number of variables it involves can spiral out of control more quickly than you might think:
- What content should be included?
- Where should this content be retrieved from?
- How many posts should be included?
- Will the aggregation be subdivided into pages?
- How should the posts be ordered? Should there be controls for visitors to order by a different criterion?
- Should the posts come from one category? From one tag? From more than one tag?
- Should they be filtered for permissions?
- Should they be filtered by date?
- Are there any other criteria that they should be filtered for?
These variables are usually quite simple for a developer to code, but they get very complicated for an editor to configure via an interface.
The Drupal Views module provides a wonderful example of this basic complexity. Views is a module that allows editors to create dynamic aggregations of content by configuring search parameters and formatting information. It provides an enormous number of options in order to provide editors with extreme flexibility.
Views has been developed over many years, and the interface has been through several rewrites with the goal of making it as simple and usable as possible. However, complexity remains. There’s simply a basic, unresolvable level of complexity that goes with the flexibility that Views offers. Fisher-Price doesn’t make a “Nuclear Fission Playset” for the same reason – all the bright primary colors in the world aren’t going to make splitting the atom any less complicated.
Consider the interface presented below. You could very easily spend an entire day training editors on just the functionality that Views offers.

Drupal Views module configuration – note that many of the buttons and hyperlinks hide entirely different subinterfaces for those particular aspects of the aggregation
Developers have it easier, since code is more succinct and exact, and they’re more accustomed to thinking abstractly about information concepts and codifying those abstractions. That said, the quality of the APIs provided varies greatly. Some are elegant, succinct, and comprehensive, while others are awkward, verbose, and have frustrating gaps that prevent even a developer from aggregating the desired content in the desired format.
A Summary of Content Aggregation Features
Here are some questions to ask about the content aggregation features of any CMS:
- What is the core content geography in use by the system? Does it have a master aggregation model, into which all content is structured?
- Can parent/child relationships be easily represented?
- What abilities do developers have to aggregate content by code?
- What abilities do editors have to aggregate content by configuration in the interface?
- What secondary aggregations, such as categories, tags, menus, and lists, are available?
- Can editors create static aggregations?
- Are these aggregations flat or hierarchical?
- Can static aggregations be manually ordered?
- Can static aggregations be limited by type?
Why Information Grows: The Evolution of Order, from Atoms to Economies by César Hidalgo (Basic Books)
“Tabular” in reference to “tables,” not “tabs.”
This could almost be viewed as the absence of any geography, since searching by type doesn’t imply any spatial relationship to content. Nevertheless, it’s quite common as a primary method of organization.
It was Timothy Dalton, for the record. This has been definitively and conclusively settled for all eternity and is now simply a nonnegotiable fact. If anyone disagrees, show them this footnote and back away slowly.
The direct exhortation to “externalize memory” came from The Organized Mind by Daniel Levitan (Penguin). David Allen has talked about the same thing in the discussion of “collection systems” in his book Getting Things Done (Penguin).
And I hope it’s obvious by this point that a content tree geography is one big, hierarchical content aggregation. It just happens to be the core aggregation for many CMSs.