Content Modeling
At the risk of triggering bad memories, consider the form you have to complete at the local Department of Motor Vehicles when renewing your driver’s license. You’re envisioning a sheet of paper with tiny boxes, aren’t you?
But what if it wasn’t like that? Imagine that instead of a form, you just got a blank sheet of paper on which you’re expected to write a free-form essay identifying yourself and providing all the information you can think of. Then someone at the DMV sits down to read your essay and extract all the particular information the DMV needs. If the information isn’t there – for instance, you forgot to include your birthdate because no one told you to put it in your essay – they send you back to try again.
You might have thought it impossible to make the experience of renewing your driver’s license worse, but I’d wager that this process might accomplish just that.
Thankfully, the DMV has forms with separate boxes for you to input different information: your name, your birthdate, etc. These boxes even have labels describing them and prompts to ensure you enter the information in the correct format: there might be “mm/dd/yyyy” in the birthdate field, two dashes in the Social Security number field, and checkboxes for “male” or “female.”
The people who designed this form considered the range of information they needed from people, and then structured it. They broke it into separate boxes on the form, and took steps to ensure it was entered correctly.
Put another way, someone “modeled” the information the DMV requires. They extracted an explicit structure from the amorphous chunk of information the DMV needs, broke it down into smaller pieces, and provided an interface for managing it (the form itself).
Similarly, a core goal of any CMS is to accurately represent and manage your content. To do that, it has to know what your content is. Just as you can’t build a box for something without knowing the dimensions of that thing, your CMS needs to know the dimensions of your content to accurately store and manage it.
In most cases, you start with a logical idea of the content you need to manage in order to fulfill the project requirements. For instance, you know that you need to display a news release. This is a general notion of content. But what is a news release? What does it look like? How is it structured? Ask five different people and you might get five different answers.
A CMS can’t read your mind (much less the minds of five different people) and therefore has no idea what you think a news release is. So, this logical notion of a news release needs to be translated into a concrete form that your CMS can actually manage.
To do this, you need to explain to the CMS what a news release is – what bits of information make up a news release, and what are the rules and restrictions around that information? Only by knowing this will your CMS know how to store, manage, search, and provide editing tools appropriate for this content.
This process is called content modeling. The result is a description of all of the content your CMS is expected to manage. This is your content model.
Content modeling is often done poorly, either through mistakes in judgment or because of the built-in limitations of a particular CMS. The stakes can be unfortunately high. Content modeling is the foundation on which a CMS implementation is built. Mistakes made here breed multiple future problems that can be tough to recover from.
Data Modeling 101
Modeling is not unique to content management. “Data modeling” has been around as long as databases. For decades, database designers have needed to translate logical ideas of information into database representations that are in an optimally searchable, storable, and manipulatable format.
The similarities between traditional databases and content management are obvious: both are systems to manage information at some level. In fact, CMSs are usually built on top of a relational database. Almost every CMS has a database underneath it where it stores much of its information.
In this sense, a CMS might be considered a “super database,” by which we mean a database extended to offer functionality specific to managing content. In fact, a friend once referred to a CMS as a “relational database management system management system” to reflect the idea that the CMS wraps the basic data management features of a database in another layer of functionality. As such, many of the same concepts, paradigms, benefits, and drawbacks of relational databases also apply to content management systems in varying degrees
Another word for the process of transforming logical ideas into concrete data structures is reification, which is from the Latin prefix res, which means “thing.” To reify something is literally “to make it a thing.”
Computers don’t understand vagueness. They want hard, concrete data that’s restricted so they know exactly what they’re working with. Reification is a process of moving from an abstract and unrestricted idea of something to a concrete representation of it, complete with the limitations and restrictions this brings along with it.
A classic example of a modeling problem is a street address:
123 Main Street
Suite 1
New York, NY 10001
This is quite simple to store as a big lump of text, but doing so limits your ability to ask questions of it:
- What city are you in?
- What floor of the building are you on?
- What other businesses are nearby?
- What side of the street are you on?
To answer these questions, you would have to parse – or break apart – this address to get at the smaller pieces. These smaller pieces only have meaning when they’re properly labeled so a machine knows what they represent. For example, the “1” in the second line makes perfect sense when it refers to a unit number, but doesn’t work as a zip code.
Consider this alternative model of the preceding address:
- Street number: 123
- Street direction: [none]
- Street name: Main
- Street suffix: Street
- Unit label: Suite
- Unit number: 1
- City: New York
- State: NY
- Postal Code: 10001
By storing this information in smaller chunks and giving those chunks labels, we can manipulate and query large groups of addresses at once. What we’ve done here is reify the general idea of an address into a concrete representation that our CMS can work with.
Couldn’t you just parse the address every time you wanted to work with it? Sure. But it’s much more efficient to do it once when the content is created, rather than every time you want to read something from it. Common sense says that you’ll read content far more often than you’ll create or change it. Additionally, when it’s created, a human editor can make proactive decisions about what goes where instead of a parsing algorithm taking its best guess.
It’s worth noting that by creating a model for the address, we’ve actually made it less flexible. As inefficient as storing the big lump of text may be, it’s certainly flexible. A big lump of text with no rules around it can store anything, even an address like this:
123 Main Street South
Suite 200
Mail Stop 456
c/o Bob Johnson
New York, NY 10001-0001
APO AP 12345-1234
This address wouldn’t fit into the model we created earlier. To make that model work for this content, we’d need to expand our model to fit. For instance, we’d need to create a space for APO/FPO/DPO numbers
Addresses in this format might be relatively rare, but when creating a content model, your judgment is an unavoidable part of the process. Is this situation common enough to justify complicating the model to account for it? Does the exception become the rule? Only your specific requirements can answer that.
While most problems seen in poor implementations involve under-structured content, know that you can go in the other direction as well. Structuring content too much can damage the editorial experience.
Former CMS architect and current UX author
The big advantage to structuring content, of course, is that it lets you repackage it and present it in different forms and contexts. The downside is that it forces editors to approach their content like machines, thinking in terms of abstract fields that might be mixed and matched down the road. The benefits often outweigh this usability cost if you’re going to present the content elements in multiple contexts and/or offer various sorting options with a large number of elements. If not, then I typically go with [less structure]
.
The key, as always, is a balance driven by a solid understanding of your content, your requirements, and your editors.
Data Modeling and Content Management
Every CMS has a content model. Even the simplest CMS has an internal, concrete representation of how it defines content.
The simplest model might be a wiki, where you have nothing but a title and a body of text. Simplistic and rigid as this is, it’s clearly a predefined content model.
The original blogging platforms – the early WordPress, Movable Type, Blogger, etc. – worked largely the same way: everything you put into the system had a title, a body, an excerpt, and a date. Since the only thing they needed to manage was a series of blog posts, this was effectively a built-in content model designed specifically to fit the requirements of that content.
In most cases, you need more flexibility than this. You need to store information beyond what’s offered by default. When this happens, you’re limited by the content modeling features of your CMS.
Some systems offer a limited number of “custom fields” in addition to the built-in model, while other systems assume nothing and depend on you to create a content model from the ground up. To this end, they can offer a dizzying array of tools to assist in content model definition.

A free-form custom fields interface in WordPress
the unspoken standard that most cmss are chasing is that of a custom relational database, which has been the traditional way to model data and information since the early 1970s
Why aren’t all CMSs like this? Because it’s often more than you need. The CMS industry has evolved around common content problems, and has created patterns for dealing with situations that are seen over and over again. Most web content management problems will fall within the range covered by these patterns – the exceptions are…wait for it…edge cases – so they’re enough to function well under most requirements.
Where a particular CMS falls in the range of modeling capabilities has a huge impact on the success or failure of your project. Some projects have complex content models and absolutely hinge on the ability of the CMS to represent them accurately. In these cases, content modeling limitations can be hard to work around.
Separating Content and Presentation
It’s tempting to look at some form of your content – your news release rendered in a browser, for instance – and say, “This is my content.”
But is it? In a pure sense, your actual content is the structure and words that make up the news release. The information in your browser is just a web page. So, are you managing content or are you managing web pages?
I argue that it’s the former. Your content is as close to pure information as possible. The web page is actually a piece of media created by your content. Put another way, it’s simply a representation of your content.
Your content has been combined with presentational information – in this case, converted to HTML tags – and published to a specific location. Ideally, you could take those same words and use them to create a PDF, or, after publishing your web page, you could use the title of your press release and the URL to create a Facebook update.
These publication locations (email, web, Facebook, etc.) are often called channels. The media that is published to a channel might be referred to as a rendition or a presentation of content in a particular channel.
The relationship of content to published media is one to many: one piece of content can result in many presentations. In that sense, a presentation is applied to content in order to get some piece of published media.
We can only do this if we separate our content and our presentation, which means modeling our core content as “purely” as possible. Ideally, we do this without regard to any particular presentation format. (We might need to add some extra information to ease the application of a particular presentation, but this information won’t be used in other presentation contexts.)
This concept is not new. Gideon Burton, an English professor at Brigham Young University, has traced this all the way back to the ancient Greeks.
Aristotle phrased this as the difference between logos (the logical content of a speech) and lexis (the style and delivery of a speech). Roman authors such as Quintilian would make the same distinction by dividing consideration of things or substance, res, from consideration of verbal expression, verba
.
Our content is logos, and the presentation method is lexis.
Binding your content to a specific presentation drastically limits what you can do with that content. If your requirements are simple and won’t change, then perhaps this isn’t a great disadvantage. But when content is structured well, its utility increases:
- Templating is easier: Having content in smaller chunks allows you to use it in more specific ways when templating. Want to display an author’s last name first on the bio page? This is much easier to do if the last name is stored separately from the first name.
- Mass presentation changes are possible: Should author headshots and bios appear in the left sidebar now, rather than at the bottom of the article? If this information is separable from the main body of content, this is a simple templating change, whether you have 10 or 10,000 articles.
- Content can be easily presented in other contexts: When your pages have isolated summaries, these can be posted in other contexts with shorter length requirements, or content can be shortened for environmental limitations such as mobile devices.
- Editorial usability is improved: Granular content models often allow you to customize the editorial interface with specific elements to allow editors to accurately work with specific pieces of information that make up your content. Should you limit the HTML tags that editors can use when writing their article summaries? If Summary is its own attribute, this is easier to do.
Going back to Burton’s Aristotelian example, Aristotle might have a theory about man’s position in the universe. This theory is his content. He can “render” this content into an essay, a play, a speech, even a drawing. Those items are the media generated from his content. They’re just presentations – the core concepts of Aristotle’s theory underlie them all.
The “Page-Based” CMS
A core question is whether your CMS is managing content or pages. Does your CMS assume every piece of content in the repository should result in a web page? Or are they pure content objects that can then be embedded into pages?
The conflation of content object and page has resulted in the phrase “page-based CMS” being used to describes CMS that explicitly manages web pages, over more abstract notions of content without presentation. The phrase normally pops up when comparing two systems and is usually meant pejoratively, with the assumption that managing simple pages is less noble and sophisticated than managing pure content.
This is a fair point, but it might be misplaced, for a couple of reasons.
First, while multichannel publishing and content reuse is very valuable, not all instances need it. In many cases, 99% of content views will be page views in a browser, so managing the page is of utmost importance.
Second, just because a CMS manages pages doesn’t mean the content in those pages can’t be used in other ways. Even if your CMS offers you a content type called News Article Page, that doesn’t mean that content can’t be extracted and repurposed into things like RSS feeds and web APIs.
While a true page-based CMS will likely bake in some web-page-specific properties – META tags, menu labels, template selection, etc. – it will also include more neutral, presentation-free information that can be used in other ways.
In the end, the difference between a “page” and a more generic “content element” seems to be one of URL addressability. Pages get URLs and are intended to be viewed in isolation, as the main content object resulting from a single web request. Content elements (non-pages) are meant to exist in support of other content through referencing or embedding (see <
Defining a Content Model
A content model is defined by three things:
- Types
- Attributes
- Relationships
These three things, used in combination, can define an almost infinite variety of content.
Content Types
A content type is the logical division of content by structure and purpose. Each type serves a different role in the model and is comprised of different information.
Humans think in terms of types every day. You label specific things based on what type of thing they are – in terms of “is a”:
- This three-bedroom, two-bath Colonial is a building.
- This 2015 Colnago AC-R Ultegra Complete is a bicycle.
- This Footlong Firebreather is a burrito.
In thinking this way, we’re mentally identifying types. We understand that there are multiple bicycles and burritos and buildings in the world, and they’re all concrete representations of some type of thing. We’ve mentally separated the type of thing from a specific instance of the thing.
Editors working with content think the same way. An editor wants to create a new News Release or a new Employee Bio
Whether explicitly acknowledged or not, whenever you work with content you have some mental conception of the type of content you want to manage. You mentally put your content into boxes based on what that content is.
A content type is defined to your CMS in advance. Most CMSs allow multiple types of content, but they differ highly in terms of how granular and specific they allow the definitions of these types to be.
All content stored by a CMS will have a type. This type will almost always be selected when the content is created – indeed, most CMSs won’t know what editing interface to show an editor unless they know what content type the editor is trying to work with. It is usually difficult to change the type of a content object once it’s created (more on this in the next section).
It’s important to draw a clear line between a content type and a content object. A content type is a pattern for an object – bicycle, burrito, or building, from the previous example. You might have a single content type from which thousands of content objects are created.
Consider making Christmas cookies. You have a cookie cutter in the shape of a Christmas tree, candy cane, snowman, or whatever. Using this, you cut cookie dough. You have one cookie cutter, which you use to create dozens of cookies. The cookie cutter is your content type. The actual cookies are the content objects.
A content type can be considered the “pattern” for a piece of content, or the definition of the information a particular type of content requires to be considered valid. An Employee Bio, for example, might require the following information:
- First Name
- Last Name
- Job Title
- Hire Date
- Bio
- Manager
- Image
(These are attributes, which we’ll talk about shortly.)
You must create this definition in advance so that your CMS knows what information you’ll be putting into what spaces.
There are multiple benefits to organizing your content into types:
- Structure: Different content types require different information to be considered valid. A Person requires a First Name. This doesn’t make sense for a Page.
- Usability: Most CMSs will automatically create an editing interface specific to the type of content you’re working with. When editing the Hire Date in an Employee Bio, for example, the CMS might render a date selection drop-down.
- Search: Finding all blog posts is quite simple when they all occupy the same type.
- Templating: Our Employee Bio pages will be clearly different from our News Release pages. Since the two types store different information, they obviously have different methods of outputting that information.
- Permissions: Perhaps only the Human Resources department can edit Employee Bios. Depending on the CMS, you might be able to limit permissions based on type.
In these ways, the content types in a CMS implementation form boundaries around logically different types of content, allowing you to apply functionality and management features to just the types for which they apply.
Switching types
Switching the underlying content type after a content object has been created from it can be logically problematic.
Let’s assume that we created a piece of content from our Employee Bio content type. Now, for whatever reason, we want to convert this to a News Release. We have a problem because we have information specific to the Employee Bio type that doesn’t exist in the News Release type (First Name, for example), which means that when we switch types, this information has nowhere to go. What happens to it?
Because of this, switching content types after content has been created is often not allowed. If it is, you have to make hard decisions about what happens to information that has no logical place in the future type.

Converting content types in Episerver – when the new type doesn’t contain matching attributes for everything defined on the old type, hard questions result
Oftentimes, you must swallow hard and give the system permission to simply throw that information away. As such, switching types is not for the faint of heart, especially when you have hundreds or even thousands of content objects based on a specific type.
Attributes and Datatypes
Content types are wrappers around smaller pieces of information. Refer back to our previous definition of an Employee Bio. An Employee Bio is simply a collection of smaller pieces of information (First Name, Last Name, etc.).
Nomenclature differs, but these smaller pieces of information are commonly referred to as attributes, fields, or properties (we’ll use “attribute”). An attribute is the smallest unit of information in your content model, and it represents a single piece of information about a content object.
Each attribute will be assigned a datatype, which limits the information that can be stored within it. Common basic datatypes are:
- Text (of varying length)
- Number
- Date
- Image or file
- Reference to other content
Depending on the CMS, there might be dozens of possible datatypes you can use to describe your content types, and you might even be able to create your own datatypes, which are specific to your content model and no other.

Predefined types of attributes available for eZ Platform
Referring back to our previous model, we can apply the following datatypes:
- First Name: short text
- Last Name: short text
- Job Title: short text
- Hire Date: date
- Bio: rich text
- Manager: reference to another Employee Bio object
- Image: reference to an image file
By specifying datatypes, you allow your CMS to do several things:
- Validation: The CMS can ensure that the information you enter is valid. For instance, Manager must be a valid reference to another Employee Bio object. Additionally, the CMS may warn you against deleting that other object while there are still outstanding references to it.
- Editing interface generation: The CMS can render different interface elements to enable you to easily work with different attributes. You might allow rich text
in your Bio attribute, which means displaying a WYSIWYGfootnote:["What You See Is What You Get.” A WYSIWYG editor is a rich text editing interface that generates HTML but allows you to edit the text visually, instead of using tags or other markup.] editor with editing controls. - Sorting and filtering: The CMS understands how to use different datatypes to sort and filter content. By filtering and sorting by Hire Date, you could locate all employees hired between two dates, and order them by seniority.
Some CMSs do not allow the datatyping of attributes, but this is rare. In these cases, the CMS normally allows you to simply declare “custom fields,” which it stores as simple text. The utility of these fields is extremely limited, as you must ensure editors enter the values correctly (enforcing a date format in a simple text field is tricky) and you must jump through hoops to use these values when sorting and filtering.
Built-in Attributes
Most CMSs will have a handful of built-in attributes that automatically exist in every content type and don’t have to be explicitly added to the content model. These include:
ID: Without exception, every content object has some type of identifier that uniquely identifies that content, not unlike the primary key in a database table (in fact, behind the scenes, this is often the primary key of a database table). Most systems have numeric, incremental IDs. Some others use GUIDs
, which is helpful when moving content between installations since they’re guaranteed to be globally unique. Title or Name: Most systems will have some way to name a content object. Usually this is an explicit Title field, which either is used only as an internal title or is dual-purposed as the displayed title of the object (the headline of a News Release, for example). In some cases, the system will allow you to derive this value from other attributes using tokens which are replaced with values. For example, specifying the Name of an Employee Bio as `$LastName, $FirstName`` will always set the Name to something like “Jones, Bob” whenever the object is saved.
Body: It’s very common to have a rich text field automatically available for the “body” of the object, whatever that might mean for the particular type. This assumes that most objects will have a free-form Body field, which is valid in many cases. Some types will not, and these systems usually have a way to hide the field for those types when necessary.
Teaser or Summary: While less common than the body field, some systems will provide a smaller Summary field. This is quite common with systems that have blog roots, such as WordPress.
These built-in attributes, where available, are automatically present in all types, and your content model is composed of the attributes that exist in addition to these.
Attribute Validation
To ensure information is entered correctly, it needs to be validated, which means rejecting it unless it exhibits the correct format or value for its purpose.
Basic validation is enforced via the datatype. If something is meant to be a number, then it has to be entered as a valid number. Additionally, the editing interface might enforce this by only displaying a small text box that only allows entry of numeric characters.
However, the datatype doesn’t tell the entire story. What if our number is only a number in format, but our intention for this number is for it to be a year? Then we potentially need to validate it in other ways: against the value, the pattern, or via some custom method.
We can validate values through ranges. In our year example, it most likely needs to be a four-digit, positive integer (depending on whether or not we’re allowing dates BC, or dates after 9999 AD), and it most likely needs to be within a specific range. For instance, we may require that it be in the past, or that it be within a particular defined period (e.g., from 100 years in the past to the current year).

Numeric validation options in Drupal
Alternatively, perhaps we’re storing a product stock-keeping unit (SKU), and we know that this must always be a pattern of three letters, followed by a dash and four numbers. A regular expression (discussed more in Editorial Tools and Workflow) of [A-Z]{3}-[0-9]{4} can ensure we only accept data matching this pattern.
Beyond simple validation, occasionally it becomes necessary to validate input through custom integration. Perhaps our product SKU needs to be cross-checked against our product database to ensure it exists. In this case, when an editor saves a content object, the CMS performs a query against the product database to ensure the product SKU exists, and rejects the content if it doesn’t. Querying your product database is a requirement that is needed by no other customer of your CMS, so it will clearly not support this out of the box. The best a system can do is provide you with the ability to program around it using the API.
Value, pattern, and custom validation capabilities differ widely. If appropriate methods are not available, then the only solution is to train editors well, and provide graceful error handling if they enter something incorrectly.
Using Attributes for Editorial Metadata
Attributes usually store information that is either displayed to the information consumer or used to directly affect the presentation of content. However, there is a valid case for using attributes to store administrative or “housekeeping” information.
Metadata means “data about data,” which means data that isn’t the primary purpose of the content object, but serves some secondary purpose. The idea of metadata in web content management is a little abstract – systems don’t usually call anything metadata and instead just treat all attributes the same – but it can be accurately used to refer to data that isn’t related to the content object directly, but rather is about the management of that object.
For example:
- A text attribute called To Do might be used to keep running notes, wiki-style, of things that need to be done with that content. A report could generate all content with some value in this attribute, which represents all content that needs some attention.
- A user selection called Content Owner could indicate what person in the organization is ultimately responsible for that content.
- A date attribute called Review By could indicate when the content needs to be reviewed for accuracy. Combined with the Content Owner attribute, a report could show a user all the content for which that user is responsible that needs to be reviewed
.
Content Type Inheritance
If content types are simply wrappers around sets of attributes, then it follows that we must create a new content type for every possible combination of attributes in our content model. This makes sense, since a News Release uses a fundamentally different set of information than an Employee Bio.
But what if two content types are very similar? Many times, you’ll have a content type that is exactly like another type, except for the addition of one or two extra attributes.
Consider a basic Page content type that represents the simplest content we can come up with – a basic page of rich text with a title. It consists of nothing but:
- Title
- Body
As mentioned previously, these will often be simply built-in attributes.
For our blog, we need another type for Blog Post. It needs:
- Title
- Body
- Summary
- Published Date
Do you see the similarity? A Blog Post is simply a Page with two extra attributes. You could do this for many different types of content. A Help Topic, for example, could be a Page with the addition of Software Version and Keywords. An Event could be a Page with the addition of Start Date and Location.
Now suppose that some time after your site launches, your marketing manager asks you to add an SEO Description to all the pages on the website. You’re faced with the prospect of adding another attribute to all the types in your content model (and then deleting it when the marketing manager decides he doesn’t want it anymore).
Wouldn’t it be helpful if you could inherit the attribute definition of Page and simply specify what attributes are available beyond that?
So, the definition of a Blog Post would be “everything a Page has, plus Summary and Published Date.” By doing this, you would ensure that whenever the Page content type changed (via the addition of SEO Description, in this case), the Blog Post type – and all other types inheriting from Page – would change as well.

A base type of Page provides the Title and Body to every type that inherits it: Blog Post, Event, and Help Topic get Title and Body, and then add to them with specific attributes of their own
Sadly, content type inheritance is not common in CMSs. Few systems currently offer it, though it seems to become slightly more common every year.
Partial type composition
What’s even rarer than simple inheritance is the ability to combine multiple types (or partial types) to create a new type. For instance, we could define a Content Header type as:
- Title
- Subtitle
Does this make sense as a standalone type? Probably not – what content just has a Title and a Subtitle? However, when defined as a part of a larger type, this makes more sense. Many types might use a Title and a Subtitle as part of their definition.
To this end, we might define an Article Body as:
- Body
- Image
- Image Caption
And we might define an Author Bio as:
- Author Name
- Author Bio
- Author Image
We might then define an Article type as simply the combination of all three:
- Title
- Subtitle
- Body
- Image
- Image Caption
- Author Name
- Author Bio
- Author Image

The Article content type is composed of three partial types, which can also be used to compose other types; any changes to a partial type are reflected in any type that uses it
How are we any better off in this situation? because we can reuse the parts to define other types. for example, we could use our content header type in an image gallery type, since title and subtitle are common to both that and an article. then, if we added something to content header, it would be added to all types that use that type
Again, this ability is rare, but where available it vastly increases the manageability of a complicated content model.

Multiple type composition in Sitecore – partial types (called “templates” in this system) can be browsed and selected in the left pane, and then added to the right pane to form a type composed of multiple partial types
Content Embedding
Some systems allow for the embedding of one content item into another item, either within rich text content or in data structures that render lists of referenced content. The embedded content is often called “blocks” or “widgets”
Rich text embedding
Consider a project that requires a Photo Gallery page. You can easily model a Photo Gallery type with a Title, perhaps an introductory paragraph of text at the top (Description), and the images for the gallery underneath that.
Then suppose the editors say, “Well, we’d like to have another paragraph of text at the bottom of the page, underneath the gallery.” You can handle this by changing the Description attribute to Upper Description and Lower Description, then altering the templating to display both, above and below the gallery.
Back to the editors: “Now we have some situations where we want more than one gallery on a page.”
Now what?
Perhaps the better solution is to model the Photo Gallery type as an element that can be embedded in rich text. This means the Photo Gallery might no longer be a URL-addressable page, but rather an embeddable content element (again, a “block” or “widget” in many cases) that gets wrapped in a page. Using this, the editors could write their page of content as rich text, and embed an object of this type of content within it.

Content is embedded in rich text by placing a reference or token that identifies the embedded object; during templating, this token is detected and replaced by some templated view of the embedded object
Beyond enabling what the editors require for this specific instance, this has two other advantages:
Photo Gallery objects can be used on multiple pages. One gallery could be embedded on 100 pages across the site.
Photo Galleries can be embedded into objects based on other types, assuming they also allow for embedding. A gallery of Bob’s karaoke performance at the Christmas party can be added to the rich text on his Employee Bio page, for instance.
The actual process of embedding ranges from simple text shorthand to sophisticated drag-and-drop interfaces.
WordPress, for instance, has something it calls “Shortcodes,” which are text snippets that are processed during output. For example:
[photo_gallery folder="images/2015-christmas-party"]
If you wanted tighter control over the gallery, you might model it as a content type, then use a Shortcode to refer to the ID of that content:
[photo_gallery id="1234"]
The corresponding PHP function would retrieve content object #1234 and use the data to render a photo gallery.
Some systems go so far as to create HTML-like syntax that allows editors to write markup inline. The Articles Anywhere plug-in for Joomla!, for instance, provides syntax like this for embedding the most recent three articles from a specific category (category #9, in this example):
{articles cat:1-3:9}
{title}
{text:20words:strip}
{readmore:More...|readon}
{/articles}eZ Platform uses a framework called Custom Tags, which allows for the embedding of data through a validated form. While this embedding doesn’t use any content, consider the content modeling we might avoid by having this functionality. If not for this method, the content type might have to be modeled with attributes for Show Twitter Icon, Show YouTube Icon, etc. And, even then, how would the author indicate where on the page they should be embedded?

Custom tag embedding in eZ Platform: the data from the form is encapsulated in the custom tag embedded between two paragraphs
A smaller number of systems provide graphical interfaces for embedding content. Content can be created, then dragged into rich text editors for placement.
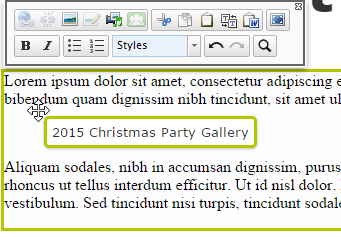
A custom photo gallery block being dragged between paragraphs in Episerver’s WYSIWYG editor - this is a managed content object, and will be rendered as a photo gallery during content output
Blocks, widgets, and regions
Blocks or widgets can sometimes be stacked into structures we’ll call lists. These lists hold one or more elements, which are rendered individually from the top down at designated locations on a template.
Content types might have element lists as attributes, or a template might have “regions” or “dropzones” into which elements can be added or dropped. These regions might be content-specific (“Right Sidebar for Content #1234”) or global (the site-wide footer).
For example, Episerver will allow an attribute type of Content Area. This allows the “stacking” of content elements inside of it. So, an attribute called Right Sidebar Content might allow editors to add miscellaneous content elements, which are then rendered in a specified location on the content type’s template.
Drupal has extensive functionality for “blocks,” which can be added to regions on a template. Likewise, WordPress offers “widgets” that can be stacked into specific regions on the template.
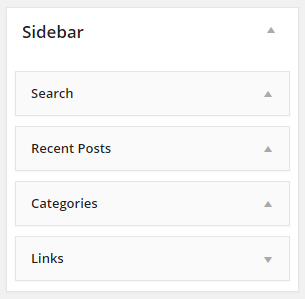
A list of widgets stacked into a template region called “Sidebar” in WordPress – the widgets can be reordered as desired
Implications for page composition
Both methods of embedding enable a form of dynamic page composition. One imagines editors as artists, painting on a canvas from a palette of element options.
The idea is seductive. Think back to our Photo Gallery example from earlier – we vastly increased the utility of this content by turning it into an embeddable object. Instead of it being a “destination,” it became content that now supports and enriches other content.
So why shouldn’t we do this for everything? We could create a single master type of Page, and all other content types could be embeddable types that go into regions on it – either lists, or rich text.
Systems like this do exist. They often have simple URL-addressable pages that are nothing but collections of lists or dropzones to which blocks or widgets are added. Other systems treat pages almost as folders that contain individual content elements which are assigned to areas on a template – a page is simply a container of individual content items that are looped over, which each item rendered individually to form a page.
While this seems ultimately flexible on the surface, it never seems to work as well at a large scale as one might hope.
First, this paradigm introduces more steps into the editorial process. If you want to publish a blog post, now you have to create a Page, then find the Blog Post content type and place it into the page. To get around this, some of these systems implement templates or even macros that automatically provide commonly used combinations of page and widgets.
Regardless of how the page started, this model also lets editors have aesthetic control over the page that they might not have been intended to have. If our macro or template has put a Related Content widget in the sidebar by default, can an editor delete this?
The fact is that a lot of content was simply designed to be templated. If you have 10,000 technical notes on your website, you likely don’t want editors to have any control over presentation. Allowing editors to change the page layout for one of them on a whim is a governance problem just waiting to happen.
Additionally, embedded content isn’t as easily available as other content, due to the lack of URL addressability, among other things. What if we wanted to send a link to our photo gallery? It’s not a page, remember, it’s just embedded in a page. And remember too that it might be embedded in 100 pages, so which one is the canonical page for it? You might say that we’ll just put it on one page and indicate that this is the one and only page on which it appears, but that then calls into question whether it’s a separate content object at all. When a widget is irrevocably bound to a single container, is it really a widget, or is it just part of the model for that type?
This also complicates APIs and content migration. Content is now buried one or more levels deep in another construct. The relationship of widgets to regions (and their ordinal position) and then finally to pages is something that has to be accounted for whenever manipulating content from code.
Finally, it introduces some interesting logical questions about the relationship between content and presentation. If an editor drags a particular widget onto a page, does this widget have anything to do with the content itself, or is it related to the page on which the content is embedded? Does the News Article object “contain” that widget, or is the page itself a higher-level object that contains both the News Article and the widget?
A widget that tells me the current temperature might be handy, but does it have any relationship to the news article on the same page introducing the new CEO? Does it need to be managed in the same logical “space” as the news article? If I delete the article, what happens to the widget? Does one need to care about or even be aware of the other? Is their appearance on the same page simply incidental?
Contrast this with a widget that lists additional content about the new CEO. It could be argued that this has a logical relationship to the news article, so should be somehow tied or connected to it. Thus, our Related Content widget is associated with the content, not the page.
In practice, artisanal page composition is less necessary than you might think, and not nearly the panacea you might hope. If the idea appeals to you, the correct solution is likely to find a system that offers the ability to compose pages on an exception basis when necessary, but supports solid content modeling and templating as its core, intended architecture.
Relationships
Modeling content is of two basic varieties:
Discrete: Describing a type of content internal to itself
Relational: Describing a type of content by how it relates to other content
In our Employee Bio example, we have both varieties. Attributes like First Name and Last Name are specific to a single content object only. The fact that one person’s name is “Joe Smith” has no bearing on any other content. This is the discrete, self-contained data of that content.
However, the Manager attribute is a reference to another content object, which means it is relational, or it defines how a content object “relates” to another content object.
An attribute can be a reference to another content object
Relational content modeling opens up a number of new challenges. Considering the Manager attribute again:
- You must ensure that the content object to which this attribute refers is another Employee Bio, and not, for example, the “Contact Us” page.
- Can an employee have more than one manager? This is an edge case, certainly, but if it happens, you either have to ignore it or modify the model to accommodate it. This means your Manager attribute must be able to store multiple values.
- How do you ensure the reference is valid? What if someone deletes the Manager object? Are you prepared to handle an employee with no manager?
- How do you allow editors to work with this attribute? Since this is a reference, your editors will likely need to go search for another employee to specify, which can make for a complicated interface.
Highly relational content models can get very complicated and are enormously dependent on the capabilities of the CMS. The range of capabilities in this regard is wide. A small subset of CMSs handle relational modeling well, and the relational sophistication of your planned content model can and should have a significant influence on your CMS selection.
We will discuss relational modeling more extensively in Content Aggregation.
Content Composition
Some content isn’t simple, and is best modeled as a group of content objects working together in a structure. Thus, a logical piece of content is composed of multiple content objects.
A classic example might be a magazine. We have a content type for Issue, but this is composed of the following:
- One featured Article
- Multiple other Articles
We might support this by giving our Issue content type these attributes:
- Featured Article (reference to an Article)
- Articles (reference to multiple Articles)
We can create our Articles as their own content objects, and an Issue is essentially just a collection (an “aggregation”) of Articles in a specific structure. Our Issue has very little information of its own (it might have a single attribute for Published Date, for example, and maybe one more for Cover Image), and exists solely to organize multiple Articles into a larger whole.
This is a contrived example. A much more common example requires aggregating content in a “geographic” structure, which we’ll talk about in Content Aggregation.
Content Model Manageability
Any content model is a balancing act between complexity, flexibility, and completeness. You might be tempted to account for every possible situation, but this will almost always have the side effect of limiting flexibility or increasing complexity.
For example, when working with content types, editors need to be able to understand the different types available, how they differ, and when to use one over another. In some situations, it might make sense to combine two types for the sake of simplicity and just account for the differences in presentation.
Could a Page content type double as a Blog Post? If a Page also has fields for Summary, Author, and Published Date, is it easier to simply display those in the template only when they’re filled in? If a Page is created within a Blog Post content type, then can we treat that Page as a Blog Post and give editors one less type to have to understand?
Whether this makes things easier or harder depends on the situation and the editors. If they work with the CMS often to create very demanding content, then they might be well served with two separate types. If they create content so rarely that they almost have to be retrained each time, then a single type might be the way to go.
If you don’t have the ability to inherit content types, then it’s to your benefit to limit content types as much as is reasonable. Having a content model with 50 different types becomes very hard to manage when someone wants to make model-wide changes.
It’s hard to place general rules around manageability, but limiting content types to the bare minimum needed is usually a good idea. More types means more training for editors, more templating, and an increased likelihood of having to switch types after creation (which, as we saw earlier, is problematic).
The best you can do is to keep manageability in mind when creating or adjusting your model. Examine every request and requirement from the perspective of how this will affect the model over time. Almost every change will increase the complexity of the model, and is the benefit worth it?
A Summary of Content Modeling Features
Since this chapter has been largely about the theory of content modeling, it can be hard to draw out specific features or methods of system evaluation. Here’s a list of questions to ask with regard to a system’s content modeling features:
- What is the a built-in or default content model? How closely does this match your requirements?
- To what extent can this model be customized?
- Does the system allow multiple types?
- Does the system allow content type inheritance? Does it allow multiple inheritance?
- Does the system allow for the datatyping of attributes?
- What datatypes are available to add attributes to types?
- What value, pattern, and custom validation methods are available?
- Can you add custom datatypes to the system based on your specific requirements?
- Does the system allow multiple values for attributes?
- What editorial interfaces are available for each datatype?
- Does the system allow an attribute to be a reference to another content object? Can the reference be to multiple objects? Can it be limited to only those objects of a certain type?
- What options are available for content embedding and page composition?
- Does the system allow for permissions based on types?
- Does the system allow for templating based on types?
- How close can this system get to the (usually unreachable) ideal of a custom relational database?
If you’re thinking that perhaps a background in database design would be helpful, you’re absolutely correct. To this end, I recommend Database Design for Mere Mortals by Michael Hernandez (Addion-Wesley). Even if you never have to design a traditional database, the ability to separate a data model from the information stored within it is a key professional skill.
These are methods to send mail to military and government personnel serving in remote locations. They’re acronyms for Air Post Office, Fleet Post Office, and Diplomatic Post Office.
Josh developed the Big Medium CMS for many years, and recently authored Designing for Touch (A Book Apart).
Personal communication with the author, December 2007.
See "A Relational Model of Data for Large Shared Data Banks” (PDF), by E.F. Codd.
A select few systems are literally thin wrappers around a custom database. Some CMSs just add a few fields and tables to a database of your own creation to add the extended functionality of a CMS.
Gideon Burton, "Silva Rhetoricae.”
For the remainder of the book, I will capitalize the names of content types as proper nouns. I will lower-case content objects (e.g., a particular article is an object of the type Article).
“Rich text” is often used to refer to any text that allows embedded formatting, such as bold, italics, etc. In most cases, this means HTML. A “rich text editor” is therefore assumed to be a visual editor that generates HTML in the background. However, some systems use the term “rich text” to refer to plain text fields that allow the manual insertion of HTML tags, or even shorthand formats such as Markdown.
Globally unique identifiers. A GUID is a sequence of random numbers and characters long enough to virtually ensure uniqueness. A common length is 32 digits, which is long enough to ensure that if each person on Earth possessed 600 million different GUIDs, the probability of a new GUID already existing would still only be 50%.
I read once about an intranet that used attributes such as these to “shame” content owners. When a page was rendered with a Review By date more than 30 days in the past, a notice was displayed at the top of the page: “Bob Jones is responsible for this content but has not reviewed it in 14 months. Contact Bob at extension 1234 to check if this content is still accurate.”
Note the usage of “use” rather than “inherit.” You can “inherit” from one other type. You “use” multiple types. When composing types, the relationship is one of composition, not parentage.
Note that blocks or widgets often reference managed content, but they don’t have to. They may just render non-content-related functionality on the page, such as a weather forecast, for example.