Eval Criteria # 22
By what method is the content model actually defined?
Throughout this guide, we’ve talked about building a content model as a theoretical exercise. However, in the real world, someone actually has to create your theoretical content model in an actual CMS.
How a system does this varies between two major options: UI-based and code-based.
UI vs. Code Model Definitions
Historically, most systems have forced the creation of a content model from the UI. Administrators could access an interface in the running system which allowed them to define new types and attributes.
More recently, code-first systems have come into vogue. In these systems, content and attribute types are defined in code, and the definitions exist in files on the file system. In some systems, these definitions are actual code in the native language of the CMS (a set of class definitions in C#, for example), and in other cases, the definitions are data in some structured markup language, such as XML or YAML.
Model definitions always need to be available in the repository so they can be used by the system. Models defined in the UI are created directly in the repository. With code-first systems, the definitions are in files, and the system synchronizes itself against these file definitions, usually when it starts up and initializes. Deploying a new model file will cause the application to re-initialize, perform an inventory of its existing model definitions in the repository, and change them to match the code.
If the defining code is written in the underlying programming language, then these structures are almost always used for typing purposes as well, as we discussed earlier. When template or integration developers get content out of the system, it comes out in the same structures created for defining the model in the first place.
To continue the example from above, you might define content types using a series of C# classes. Then, when templating, the operative content object is represented as an object from one of those same C# classes.
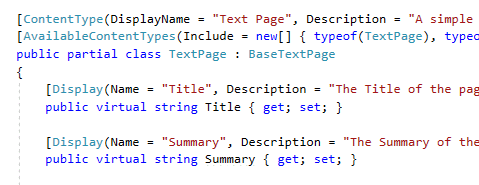
An example of code-first content definition in Episerver. This code snippet is a full C# class definition. We can see the content type (TextPage) with its name, label, and description; the type from which it inherits (BaseTextPage), the type allowed as child objects (also TextPage); and two attributes (Title and Summary) with their labels and descriptions.
In addition to defining the content type, when content objects of this type are manipulated from code, they will be represented by this class.
It’s hard to say which option is “correct,” because both have advantages and disadvantages. The market seems to be moving in the direction of code-first definitions, but there are still many systems implemented mainly from the interface and theme level, meaning very little low-level code is written. Additionally, the trend towards SaaS, cloud-based systems gives us another segment of the market where you cannot write any code.
Interface-based modeling does allow non-developers to create a content model, but there are some deep divisions over whether this is something that should be allowed. Content modeling requires some experience in data modeling and abstraction, and it can be easy to make mistakes.
Additionally, changing a content model usually needs to be accompanied by a change to other code or templating, so it’s often just one part of a complete change. An administrator might be able to change the content model, but not complete their ultimate goal because they’re waiting on a developer to change something else to which they don’t have access. Worse, they might change the model, and inadvertently break some integration code they weren’t aware of because the models now have a different structure than the code was expecting.
Code-based modeling has the limitation that only developers can create and change the model, but – for all the reasons mentioned above – this is often an advantage in terms of security and stability.
Model Definition and Development Operations
The maintenance and deployment of programming code is known as development operations (“dev ops”). These are the systems and processes by which code created by a developer is stored, combined with other code, tested, compiled, and ultimately deployed to a running system (or multiple systems) in production.
Dev ops processes are mostly file-based, meaning that files are the container by which code, configuration, and other necessary data are placed into to be transmitted from one system to another.
Clearly, code-first systems have multiple advantages here:
- The files associated with a CMS project are usually always stored in a source code management (SCM) system, so the entire model is versioned. If you want to know when a model was changed and who did it, you can consult the SCM to see when a changed file was checked in and by whom.
- Model changes can be deployed with other code changes. When modeling from the interface, you usually have to make your changes in the development and testing environments, then make the same changes in production, timed with the release of new code that depends on them. With a code-first approach, you can just release the model changes with the other code and everything deploys together.
- It’s easier to synchronize environments, especially during development. Model changes can be passed around as files, instead of requiring humans to identify and mirror sometimes subtle changes between environments.
As mentioned, this feature goes both ways. The “correct” approach depends entirely on the scenario, the technical makeup and sophistication of the team, and how often the model will change. The precision and portability of file-based assets is helpful to integrate with dev ops processes, but it clearly involves more development resources and configuration, and is much more valuable in developer-focused scenarios.
Propagating Model Changes
If a content model is not code-first, then there needs to be some other way to move model changes between environments. Clearly, a human can simply duplicate the changes via multiple interfaces, but this is inefficient. Therefore, most systems will offer some sort of model import/export.
From the source environment, you can trigger the creation of an export from the UI, and this would result in the model being serialized to a file, which is usually downloaded through the browser (though some systems will deposit it into a known directory on the file system, for integration with non-human processes). Then, in the target environment, you would upload that file, which would create the exported types.
Many systems allow the import and export of objects as well. This has nothing to do with content modeling, but in some cases, the system will include the type of every object in the export so the types in the target environment can be changed to support the incoming content.
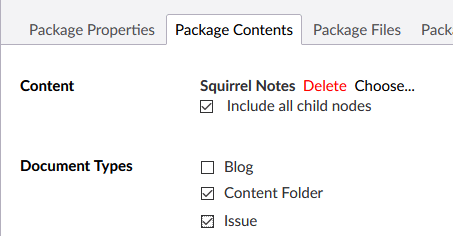
Create of an “export package” in Umbraco. In addition to the content objects to export (the “Squirrel Notes” object and all its children), I have selected supporting content types to go in the export as well, which will be created in the target environment.
What gets tricky is if the type already exists in the target environment. If so, there’s a good chance you know this and are seeking to update the type definition. In this case, how are the types being matched up? The most obvious method would be on name – if you export and upload the definition for a type named Article, this should update an existing type also named Article.
This works well, so long as source and target are aligned and kept relatively in sync. However, if the target environment has no relationship to the source environment, or the types differ wildly, then there’s a chance you’d be updating an Article that has no prior relationship to your uploaded definition, and that might turn into a mess.
In other systems, type correlation is via a globally unique identifier (GUID) or other unique identifier, which is safer and less likely to cause disruption to an unrelated type.
This code-vs-configuration debate is really about self-determination – how much should editors be able to do without developers being involved? However, this has to be balanced against manageability, stability, and all the other benefits that a more strict management approaches brings with it.
Additionally, editors wanting to model content from the interface need to consider situations when they might want to make changes, and if the scope of those change would be confined simply to a model change, or whether the model change is just one part of a larger set of changes which extend beyond what they can complete.
Evaluation Questions
- By what method is the content model actually defined? From the UI, or from code?
- If code-first, in what language or markup are the types defined? Are these same models used to strongly-type content objects?
- What capabilities exist for model synchronization between environments?
- Are content model definitions exportable/serializable into a file? Will this file import to another instance of the CMS?
- During content model import, how are target content types matched against source types in the export file? How are conflicts handled?