Eval Criteria # 19
What aggregation structures are available to organize content?
So far, we’ve talked about content modeling at the type level, based purely on attributes. Another aspect of structure is how multiple content objects are organized in relation to each other. This is often manifested in a content tree, but many systems offer other ways to organize content which might impact how it’s modeled.
The grouping and association of content is known as content aggregation.
Internal vs. External Structure
A relationship between two content objects can be referential, as we’ve discussed, meaning it’s defined by a referential attribute or a parent-child relationship in a tree. This relationship can be said to be an internal relationship because at least one of the content objects knows about it – it’s built into the attribute values of that content object.
Another type of relationship is an external relationship where two content objects are related through some structure which is external to both of them. Neither of the objects are aware they’re related in this way. The external structure can be created, exist, and be deleted with neither of the content objects ever knowing it had been associated at all.
Consider a web page that links to another web page on a completely different website. In that situation, Page A knows about Page B because it links to it. That relationship is internalized to at least one of those pages.
Consider if there was no link – I just personally decided the pages were related, so I created a bookmarks folder on my desktop, gave it a name (“Pages I Like”), and put shortcuts to both of those web pages in it. In this case, my folder is the “external structure,” and it imparts some aggregational value to both pages. I know those two pages are related in this way, and I know why from my own perspective. However, neither page is aware I’ve created this association, and if I ever delete my bookmarks folder, that relationship goes away without either page ever knowing it existed. That relationship was completely external.
When comparing internal and external relationships, the differentiating question is, does a content object have to be edited to exist in this structure? Do we edit the content object and assign it to the structure? Or do we edit the structure and assign content objects to it?
The former is an internal relationship of content, as we’ve already discussed. The latter is a type of structure we’ll discuss in this chapter.
Categories and Taxonomies
Categorization or taxonomy is an aggregational structure that allows you to organize content into groups.
From the perspective of CMS, categories and taxonomy are usually considered synonymous – it would be very rare to see both feature names in the same system. We’ll use “categories” here to represent both.
Categories tend to be a “top down” system, meaning an editor or administrator has established a list of categories in advance, and when content is edited, it can be assigned to one or more existing categories. It’s rare that editors are allowed to create categories on-the-fly. To create a new category, an editor would need to access an interface specifically for this, and access to this interface is usually restricted as an administrative function.
Categories are often hierarchical (a category tree), as it’s very common for categories to become conceptually narrower and more specific as you move “down” the tree. In some category trees, a category might be marked as non-assignable and exist solely to contain child categories.
A simple category tree in WordPress, showing top-level categories which have child categories of increasing specificity.
Your ability to search for category assignments will have considerable impact on its utility. Some common search use cases –
- What content is assigned to Category X?
- What are subcategories of Category X?
- What is the ancestor path of Category X?
- What categories is Content Object Y assigned to?
- Is Content Object Y assigned to Category X?
With a category tree, you sometimes need to consider implicit ancestral assignment. If you have a tree of concepts – moving from broader to narrower as you traverse down the tree – does assignment in a child category imply assignment to all its parents as well?
Say your category tree has “Vehicles” with a child category of “Cars” which has a further child category of “Sedans.” If you assign something to “Sedans,” it should logically be assigned to “Cars” and “Vehicles” as well. Some APIs may support this, and others won’t.
Ancestral assignment is often achieved by the ability to search for descendant assignments. From the perspective of the “Vehicles” category, it’s very basic to search for all direct assignments of that category. What’s often more helpful is to search for all descendant assignments, meaning all assignments to this category or any of its descendants.
Categories As Content
Categories can sometimes hold other information besides just a name or a label. In some systems, categories can have a description, and have links to other categories, not their descendants (“related categories”).
This sometimes raises the question: “should categories just be content?” Should we have a Category type, with a Title, Description, and a repeating ? And then every content object could have a repeating attribute for Category Assignments (assuming that reference is bi-directional).
If all these capabilities are in place, then this is a desirable option. The benefit is that categories become managed content. They can be versioned, they have permissions, and they have an entire editorial lifecycle attached to them. Additionally, they might now be URL addressable, so each category has a page where assignments can be listed.
Tagging
The basic model for categorization is also true for tagging. A tag, like a category, is a conceptual structure to which objects are assigned.
The difference in categories and tags lies mainly in editorial usage. Whereas categories are top down and planned in advance, tags are often bottom up, meaning editors can create them on-the-fly. Content objects might have an attribute for and editors can enter a space- or comma-delimited list of whatever tags they want to apply.
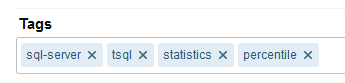
An example of tagging from the Q&A site Stack Overflow. Tags are simply entered as tokens separated by spaces (spaces inside a tag need to be replaced with a hyphen).
Architecturally, a “tag” is often just a simple text string assigned to content. Finding all content “tagged” with the same thing usually just means finding all content with the same assigned text string. There is no “central authority” for tags – a tag has no idea if other content is assigned to it. At its core, a tag is simply a “target” you can specifically search for to find similar content.
The danger of the “loose-ness” of tagging is unchecked proliferation, which can happen because there’s no governing authority like there usually is for categories. What you call a “car”, I might call an “automobile”, and someone else might call a “vehicle”. Tags will be created without any consideration to whether a similarly appropriate tag exists. To avoid this, many tagging interfaces have type-ahead suggestions or a list of existing tags to pick from.
Tags are not normally hierarchical. Occasionally, you see systems that offer a “related tag” capability, or some form of specifying an alternate tag name, so that our aforementioned “car,” “automobile,” and “vehicle” can appear to be a single tag.
To fix prior mis-assignments, some systems offer tag merging, where all the assignments for Tag A can be combined with Tag B, and Tag A will henceforth become an alternate tag name for Tag B.
Menus, Lists, and Collections
Some systems have additional structural systems like , lists, and collections. The specifics differ, but they’re usually available for ad-hoc structuring and aggregation of content.
Menus tend to be hierarchical. They often include other web navigation-specific features, like labeling, to display something other than the content’s title, and hyperlink-specific functionality like whether to open the link in the same window or a new window (the target HTML attribute) and hover text (the title HTML attribute).
Lists and collections are usually just flat, ordered lists of content objects. These can be helpful for things like specifying a list of news articles on the home page, or a list of links for overhead, static navigation.
Generally, structures like these are external to the content – to assign content, you manage the structure and select the content to be assigned. Occasionally, some systems do allow assignment to a structure from the object itself.
A pattern of tree-based systems is often to simulate these structures as branches of the content tree. Combined with the pattern of “hiding” content by not creating it as descendants of the home page, and the feature of object references, it’s quite simple to designate a branch of the tree as a menu.
You could easily model a type, with text attributes for Label Text and Hover Text, a checkbox for Open in New Window, and a referential attribute for Target Object (and even an optional External URL attribute for when you’re linking to an external site). You could create an extensive branch of these objects in the content tree, then traverse it to render navigation menus.
Aggregation structures like categories, tags, menus, and lists are the utility players of content modeling. They can be quick ways to group content for usage in ways that are completely idiosyncratic for a particular situation. It’s almost impossible to generalize their usage – they range from core categorization schemes, to one-off, ad-hoc content structures to populate content structures not able to be easily represented in other ways.
Evaluation Questions
- What aggregation structures exist to organize content? How do they differ from one another, and what is their intended usage?
- Does the system have built-in features for categorization or tagging, or both? If both, how do they differ? If not in the built-in model, do categorization or tagging attribute types exist?
- Can categories be organized into a tree?
- Can non-selectable “container” categories exist in the tree?
- Are their ways to specify implicit ancestral assignments within a category tree?
- How can the category tree be traversed and queried from the API?
- How does the tagging system help prevent unnecessary tag proliferation?