Eval Criteria # 15
What is the relationship between "pages" and "content"?
The concept of (1) a content object existing in a web content management system, and (2) that content object getting a URL at which it can be retrieved, are two separate things. However, in some systems they get combined. Understanding the relationship between a page and a content object is critical to deciding how content gets modeled.
In older systems, the idea of “pages” was often not even part of the CMS. Pages were just executable templates on the file system that pulled content into them. This gave us URLs like:
/article.php?id=42
In that case, the executable file called “article.php” was acting as the page and the content was a database record with a key of “42”. They were combined at request time, and the result was sent back as the HTTP response.
In this example, the content has no concept of a page. It doesn’t even know it’s being rendered into a page. It’s just pure data that happens to be pulled into a page rendering process at request time.
In fact, the CMS itself (insofar as a raw database is acting as a CMS) doesn’t even have any concept of the page. The request for article.php is handled by the web server. It processes the logic of responding to the request, which just happens to involve contacting a database for information.
Later, CMSs started managing the actual concept of the page itself. Pages became virtual and were no longer represented by a file on disk that was the direct target of a URL request. This seems routine now, but at the time (think, turn of the century), it was ground-breaking. It also led to the idea of “pages” and “content” getting mashed together.
Now, the CMS itself is much more intimately involved in the request process. The CMS knows that its responding to an HTTP request, and it becomes involved in the URL interpretation and content mapping required to match content with that request.
This requires a CMS to be “page aware” – or perhaps more accurately, “URL aware” – and it means there’s some link between a URL and a content object. How this link is architected, managed, and maintained is subject to several different patterns.
The Operative Content Object
Distilled down to its core, when we say “page” we really mean “URL,” or, even more generally, we mean “address” or even “query.” We’re talking about a text string to which a specific data construct is assigned and returned (in whatever form) when that string is activated in some way, whether it’s entered in a browser address bar, sent over an API, whatever.
As the risk of over-abstraction, this is simply a mapping. A URL is a “ticket” that can be exchanged for something. A data construct is assigned to a specific ticket, and the CMS matches this ticket up when it receives a request.
For most all modern, coupled CMSs, a URL is assigned to a specific content object, whether it be a Page or an Article or a Employee Bio. The operative content object is the content object to which a request is directed – this is the content object that the user specifically wants, and that the request primarily operates on.
Consider:
/news/politics/2019/08/11/china-trade-war-heats-up
That URL is clearly directed to a specific content object – an Article object, from the looks of it. The processing for the request will undoubtedly use other content to some degree, but it’s fair to say there’s a specific Article object in the repository that’s the main intention of this request.
The operative content object is rarely served “raw.” Except in headless architectures (discussed below), any response to the request is transformed via some rendering operation, such as a template execution. We’ll refer to this combination of (1) URL mapping, (2) operative content object, and (3) and rendering execution in response to a request, as a delivery context.
A delivery context is all the processing acrobatics that a CMS goes through to turn raw content into a presentable form that can be delivered to the requestor. In some systems, this might be an MVC controller. In other systems, this might be as simple as the direct access and execution of a PHP or ASP file. In other systems, this might be as simple as retrieving a file from the file system.
The operative content object might not be the only object used in that delivery context. It’s common for other objects to be “recruited” to fulfill a request, in two ways:
- The operative content object might refer to other objects via referential attributes
- The rendering template might query the repository and display information from other objects
The resulting request is therefore usually an aggregation of content; we’ll call this the content payload.
A common sequence looks like this:
- The CMS intercepts the inbound HTTP request (and thereby prevents the web server from just serving from the file system)
- The CMS determines and retrieves the operative content object to which the request is directed
- The CMS determines how that object needs to be transformed, often by finding a root template to execute
- The CMS creates and executes a delivery context of some kind; this is usually some controlling code execution and/or cascading templating execution that assembles and transforms a content payload
- The CMS sends the result of the delivery context back as an HTTP response
The specifics will vary from system to system, but the above is quite common.

The delivery context is the operation required to assemble and transform the content payload. In this example, a URL has mapped to an Article object as its operative content object.
The delivery context to fulfill this request recruits other content, either through referential attributes on the operative object () or delivery context-driven operations, like the retrieval of related content and footer information through controller or templating code. The result of the delivery context is sent back as the response to the original request.
Pages vs Content
In some systems, the concepts of “page” and “content” are separate things. Pages might not be considered actual content.
In these systems, you often manage pages explicitly, usually in a tree. These are a special data construct designed to represent a web page. In these systems, you sometimes have page-specific information (“META Keywords”, “Title Tag”, etc.) on the page construct, completely separate from the attributes of the operative content object or content payload that the page delivers.
In these systems, pages get URLs, but content is in some separate organizational structure. Content objects get assigned “into” pages. A page therefore “wraps” a content object for delivery – pages are a container for content.

In Concrete5, a page is a distinct structure, apart from the content which appears on that page. Pages contain information specific to the role of a web page, editable in a dialog shown here, but content is added to pages in specific zones (the “Add Content” option at the top).
On the other end of the scale, some systems dictate that content objects are automatically pages themselves – the content object gets a URL and is directly addressable as a page.
This “omni page” architecture operates on a spectrum. In some systems every content object is like this. Sure, you might be creating a “Person” object, but that’s also a page, whether you like it or not. This is common in web-focused systems which are said to be “page-based,” meaning every content object gets an addressable URL.
Omni-page architectures are common in web-focused systems with a primary content tree, since the format of a URL overlays nicely on the concept of a tree. (Consider: a URL is essentially a tree serialized into a text string.) Most tree-based systems will form URLs by assigning a URL segment, and crawling the tree from the content object back to the root, and concatenate these segments into a string.
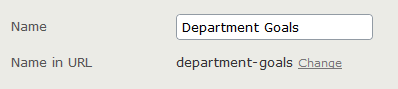
A page in Episerver, with its URL segment defined. The URL segment is an attribute of the content object, and the URL segments of the page and all its ancestors forms the URL. In Episerver, any type inherited from a specific base type is an addressable page. Episerver has another type of content (a “Block”) for content that doesn’t get a URL assignment and is therefore not directly addressable.
Really, any content that’s assigned a dedicated URL is assumed to be a page. This might not be intended, of course, but if a content object gets assigned a URL, then it can be said to be “page-ish,” at the very least. (It doesn’t matter what you call it, if it walks like a duck and talks like a duck…)
So, the extremes of this scale are:
- Systems where pages are a completely separate construct from content
- Systems where every content object is also a page
In reality, most systems lie somewhere between the two. They’ll offer some type of page architecture, but will also have content that doesn’t represent pages, and therefore isn’t URL addressable. This is preferable to the extremes, since there are times when you might want “pure” content that is never meant to be directly accessed, and other times when you have a large volume of content that should be represented in a page construct, so creating a separate page for each is inefficient and tedious.
Coupling Models
What we’ve been discussing above are traditional coupled CMSs. A coupled CMS generates a delivery context for every request and performs real-time operations to form a content payload and return the result.
There are two other models that might be considered “time-shifted” delivery contexts. They still create and execute a delivery context, they just do it in advance, save the result, and some other system – usually a simple web server – delivers that result when it’s requested in the future.
- A decoupled CMS manages content, then generates responses in advance and stores them, normally as a static HTML file
- A static site generator does the same thing, but it doesn’t actually manage content, it just executes the delivery context against an existing repository
You might say a decoupled CMS is a static site generator with a built-in content repository, or that a static site generator is a delivery context that can connect to an existing content repository. The line gets very blurry.
While saving and delivering the result of a prior delivery context is helpful for lot of reasons (performance, fault tolerance, server load, etc.), it has the drawback that it cannot respond directly to the inbound request. Since there’s one delivery context that’s saved for multiple future requests, you normally cannot alter anything in response to those requests.
A coupled CMS, by comparison, is executing a new delivery context for every request, and can inject variables into it based on things like the identity of the user, their location, their prior activity, and even things like the time of day and background data like current product pricing information.
Additionally, a headless CMS actively rejects the delivery context model altogether. It has no controlling code, no template rendering, and no content payload. You request specific content, or a specific query for content, and you get that content back, and nothing else. It’s not saving a prior context like a decoupled CMS, it just has no context at all. The content is delivered to “raw,” serialized into a structured text format like JSON or XML, directly as it’s retrieved from the repository.
So, where does the delivery context happen with a headless CMS? Wherever you decide to build it.
Part of the understanding when working with a headless CMS is it’s only a repository, and you will write a delivery context system to manage things like the URL translation to identify the operative content object, the assembly of the content payload, and any necessary rendering. You write this in a completely separate environment from the headless CMS, in whatever technology stack you like. With headless, there’s always another environment somewhere that’s actually delivering the content, be it a mobile app, a website, a display ad, etc.
For some clients, this is exactly what they want, since they’d prefer to bring their own tools and architectures to the delivery context, for whatever reason. For other clients, this involves a large amount of work to simply arrive at the same level of functionality that a traditional coupled CMS provides out of the box.

With a headless CMS, the delivery context exists apart from the CMS. The delivery context is developed as a custom app or using a non-CMS framework, and the CMS exists “alongside” it. All URL request translation and content retrieval happens outside of the CMS.
Non-Addressable Content
Without a URL, content is sometimes said to be placeless, meaning it’s not directly addressable – the implication of a URL address meaning it has a “place” and exists in some location relative to a larger context.
Consider blog comments. They aren’t normally URL-addressable, and they only exist to be rendered as part of the blog post to which they’re assigned. When a new blog comment is entered, it’s appropriate to store it as “placeless” content. The only reference a blog comment needs to a larger context is some link back to the post on which it was entered.
Other than that reference, the blog comment can just exist in some big conceptual “bin” of other comments, to be retrieved by its post link when the post is rendered.
To refer back to our prior nomenclature, a blog comment will never be the operative content object of a request. It’s never the “main point” of a request – it exists solely to support another content object (the blog post), and it’s recruited for this purpose in the delivery context.
As we discussed above, some systems are omni-page to the point where everything gets an assigned URL, even things you don’t want to have a URL (like blog comments, for example).
However, just because a content object gets a URL, you’re not absolutely required to deliver it there. A traditional, coupled CMS will resolve the URL back to that content object and deliver the data to a templating layer, but you can technically output anything you want. You control the logic of the template, so you can do whatever you need to do here.
If you have a CMS that always assigns a URL for content you never want to be directly addressable, you have a couple options:
- Your rendering template can just return a 404 (hopefully, an actual 404, but if not, then a page that resembles a 404).
- A request for that content could be redirected to where the content is actually displayed, often in the context of another object. In our blog comment above, the request could return a redirect to the containing blog post (perhaps with a bookmark to scroll down to the actual blog comment).
This entire discussion probably seems like a minor point, and it is…until it isn’t. You start a web project thinking about pages, but you’ll eventually run into content that doesn’t match one-for-one to a URL, or start delivering content to channels that don’t have any concept of “pages.” For these situations, you need to understand the content/page/URL relationship.
I have seen CMS implementations which have descended into chaos primarily because the relationship between pages and content was deeply misunderstood early in the modeling process.
Evaluation Questions
- What is the coupling model of the CMS: coupled, decoupled, or headless?
- Are pages an explicit construct in the system, separate from content objects, or are all content objects considered pages?
- If not all content is considered a page, then how and why is content assigned or not assigned a URL?