Eval Criteria # 13
Can content objects be organized into a hierarchy?
We’ve talked a bit about relationships between content objects via referential attributes. But there’s another object relationship so common it’s frequently built-in as a core feature: a parent-child relationship, in the form of an overarching content tree.
A content tree is a group of content objects organized into a hierarchy. One content object is the content root, and it contains one or more child objects, each of which might also have child objects, and so on “down” the tree.
Yes, yes, I know – it’s really an upside down tree, when visualized, which means when we talk about moving “up” or “down” the tree, it might be confusing. The content root is at the top, and levels visually open downward, which isn’t how an actual tree works, but the nomenclature has stuck.
Parent-child relationships are quite common:
- A Book object has multiple Chapter child objects
- A Department object has multiple Faculty Member child objects
- A Recipe object has multiple Ingredient child objects
- A Page object has multiple Page child objects
Generally speaking, parent-child relationships are how humans organize concepts. We move from broad concepts to more narrow concepts. A lot of our content is organized the same way.

An object tree in Sitecore. In that image are nine separate content objects, organized into a hierarchy with three distinct levels.
What a content gives us are multiple implicit relationships for every content object:
- An object can be related to one or more child objects
- Every object (except the content root) is related to a single parent object
- An object might also be related to sibling objects – children of the same parent
- Objects are often said to be “above” another object (closer to the content root), or “below” another object (further from the content root)
- Objects above an object (so, closer to the content root) are said to be ancestors of the object (one of them is both the parent and an ancestor)
- Objects below an object (so, further from the content root) are said to be descendants (child objects are both children and descendants).
- An object together with its descendants is often called a branch of the tree. (Occasionally, a content object with no children will be called a leaf or a leaf node.)
- Objects might also have a behavioral relationship with objects at the same depth or level as themselves, defined as their distance from the content root. For example, objects directly under the content root are often considered to be at a depth of 1, while their aggregate child objects (so all the children of all objects at depth 1) are considered to be at a depth of 2, etc.
- Objects directly under the content root are often called top level objects. (In web-based systems, “top level pages” is often used to refer to objects directly under the home page, regardless of that depth relative to the content root.)
What can be odd is that this is a rare case when the objects define the model, not necessarily types. So far, we’ve been talking about the structure that has arisen from content and attribute types. With a content tree, we’re discussing the structure that arises from creating actual objects and organizing them.
It’s actually quite natural, since the tree effectively creates two pseudo-attributes on every object. If any content can be organized hierarchically, then every type effectively has a referential attribute for Parent and a repeating referential attribute for Children. The tree just builds those in.
Objects vs. Folders
It’s important to note that a content tree is not a folder tree. Some systems attempt to organize content into a series of “folders,” much like a computer operating system. This is done with the idea that folders are intuitive to end users.
However, what this model misses is that a folder is usually not a content object. It’s some other data construct, that doesn’t act like a content object. For instance, it can’t be the operative object of inbound URL requests, and it often has completely different (or omitted) functionality for permissions, versioning, and workflow.
Additionally, if a folder is the only thing that can contain content, then you lose all the modeling capabilities of parent-child relationships. The only implicit relationship a folder tree offers is a sibling relationship of a content object with all the other objects in the same folder.
If you have a object tree, but your situation absolutely requires the concept of “folders,” then you’re usually able to just fake it – create a Folder type, give it a Name attribute, and allow it to contain child objects of all kinds. If your system allows it, you can even change the icon to something that looks like a folder. For many situations, this works just fine, and you still have all the aforementioned relational benefits.
Editorial UI and Object Trees
A content tree presents a natural user interface for editors. The tree is usually visually represented, and editors can open and close branches of the tree to drill down into descendants. Moving your focus up and down a tree is called traversal.
Most tree-based systems offer a way to create child objects under another object (provided the editor has sufficient permissions) via a “Create Content Here” button or something similar.
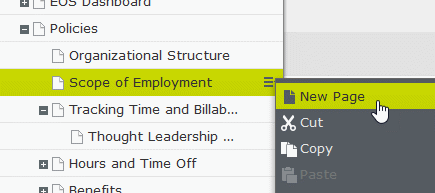
Episerver pages organized into a tree, with a “New Page” link to create new content underneath the selected parent (a page called “Scope of Employment,” in this example). Episerver also includes “Cut” and “Copy” options to allow the “pasting” content somewhere else, in addition to drag-and-drop object movement.
Many systems will also offer drag-and-drop functionality to move content objects from one parent to another.
Multi-Positional Content Trees
Back when we discussed type inheritance and composition, we talked about some problems with conceptual trees. That discussion was in the context of a type inheritance tree, but the same base problem is true of a content tree – an object can only have one parent, and sometimes this can be a problem.
For example, it’s very common to have a tree of Page objects to model web navigation. Hierarchical navigation is extremely common in websites. For example, the home page has a child page of “Products” which has multiple child pages, one for each product, each of which might have other child pages for other information. This tree structure is used to format and display navigation menus and crumbtrails – the links are created by traversing the tree from the origin point of whatever content the user is viewing.
What if a page needs to appear in more than one place? What if the navigation menu next to every product needs to include a link to download the same whitepaper? If you’re generating navigation directly from the content tree, this can get complicated. Do you create the same download page as a child of every project page? And when the page changes, do you just need to update it in every location?
Ideally, you can have the same content appear in more than one place in the same tree. This is often possible through the use of object references. An object reference is – wait for it – an object that references another object. So, you create your whitepaper download page in one place, then create a reference object everywhere else you want the page to appear, all of which point back to the original object. Changes can be made to the original object, and since the references don’t have any content of their own and just point back to the original object, they’ll all update.
There are two ways these reference objects might work –
- The reference object might actually transport the user across the tree. So, clicking on a reference object to our original whitepaper object might take the user to that original object. So the page appears in more than one location for the purposes of navigation, but it can only be viewed in its original location.
- The reference object might allow viewing in its reference location, as if the original was located there all along.
Some systems offer both options, which is helpful. Each solution has its advantages and drawbacks, and there are use cases for both.
Typed Trees
Some systems offer typed trees, whereby the parent-child relationships can be limited by type. Consider some of our examples from above:
- A Recipe can be a parent to an Ingredient, but an Ingredient should never be a parent to a Recipe.
- A Quiz can have multiple Question children, but the inverse isn’t true. Additionally, Question objects aren’t allowed child objects of any type.
By default, some systems allow all types as children of all other types, while other systems allow no children of any type. In both cases, you need to configure the type to allow certain kinds of objects, or disallow others. Systems of both kinds operate on either exclusion or inclusion – you configure a type to allow specific child types, assuming all other types are disallowed, or vice-versa.
When a tree is typed, object creation options are limited. When an editor is presented with a type selection interface, the list of types will be filtered to only those types available for creation under the parent context.
A typed tree is a form of value coercion. Remember, a child relationship is really an implicit attribute on both sides – the child gets a referential attribute to its parent, and the parent gets a repeating, referential attribute representing its children. Rather than evaluating an input after the fact, a typed tree imposes coercive validation by parentage – it prevents an invalid attribute value from even being initiated.
Hierarchical-Based Functionality
Beyond modeling, a content tree often influences other functionality and how it applies to various objects. A parent-child relationship implies some level of control from the parent over the child, and it’s common for systems to allow functionality to inherit down the tree.
Permissions, for example – in many systems, a child object will inherit the permission set of its parent, in one of two ways:
- The parent’s permission set is copied into the child object when it’s created
- The child has no permission set, and instead actively refers to its parent when its permissions are referenced. This is is generally preferable, since the child’s permissions will mirror the parent’s permissions and change in parallel.
Other functionality that might filter from parent child to child are approval sequences, ancestral URL paths, and notification options.
Like we discussed with type inheritance, this can cause unintended, systemic effects. Changing the settings on a single object can cascade all sorts of changes down that branch of the tree.
Cascading Values
Cascading attribute values is a pattern that’s inherent in tree-based organization. You can traverse the tree to find inherited attribute values that would cascade to a starting node on the tree. So, these are values inherited by an object by virtue of its position in the content tree.
In effect, attributes can cascade their values “down” the tree to the objects below them. Any attribute on any object can be accessed by all its descendants, causing that attribute to apply to an entire branch of the tree.
Consider a Section type, meant to represent a collection of pages in a website about a specific topic (“Products” for example). There might be dozens of Page objects as the nested descendants of a Section.
The Section has an attribute for If you wanted each of those pages to display the banner indicating what section they existed in, you can retrieve this by detecting the page’s position in the tree.
Remember that a Page will have an implicit reference to a Section by virtue of being its descendant. To find the owning section, you simply need to “crawl up the tree” from the Page that is being displayed toward the content root, until you find a Section. The first Section object found is, by definition, the section in which that particular page resides, and you can read the attribute from that object and display it.
This means every Page object has an implicit positional attribute. It also means that moving a page underneath another Section object will change the displayed banner, since a different Section object will be now found when searching toward the content root.
Content Trees and Websites
For web-based systems, the tree often represents a hierarchy of URL-addressable web pages. A common pattern is for the content root to be the home page, and other pages will branch out below it. This makes sense, as the tree model overlays nicely onto web navigation.
However, it can be helpful to not require the content root to be the home page of a particular website, for a couple reasons.
First, in multi-site environments, you’ll have more than one home page. In these cases, the content root is a more abstract type of content object (often just called “Root”), with multiple home pages as children. The content root literally just represents the “parent” of all content. It’s often its own type, which can be helpful to store attributes that should cascade to multiple websites (things like legal disclaimer text, API key values, etc.)
Second, in systems that don’t have a model for non-page content, it’s handy to have an area “hidden” from the URL scheme.
In web systems, a content object’s URL is often formed from its position in the tree, relative to the home page, which means something that isn’t a descendant of the home page won’t get a URL (or, it might get an invalid URL that doesn’t actually return content).
In these situations, you might have an object at the same level as the home page (so, a sibling of the home page), under which you “hide” this non-page content. The content would be injected into delivery contexts (again, we’ll talk about that term later) via code in a template or delivery context.
A content tree can be a rich source of intention and meaning. Just creating a content object as the child of another object establishes a relationship that can be referenced, traversed, and leveraged to allow functionality, access, and formatting.
Evaluation Questions
- Does the system have a built-in object tree? If not an object tree, does it have a folder tree?
- Does the tree support typing restrictions? How are these typing restrictions presented in the editorial UI?
- Is it possible for the same content object to effectively appear in two locations in the tree?
- If a web-based system, is the root object in the tree always the home page?
- What functionality is derived by placement in the tree? What functionality is cascading down from parentage?
- If a web-based system, are URLs formed by tree placement?
- Is there any built-in support for cascading attribute values, from ancestor to descendant?
- What methods of tree traversal and querying are available from the API?